 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Optimal Transformer Depth for Low-Resource Language Translation
Paper and Code
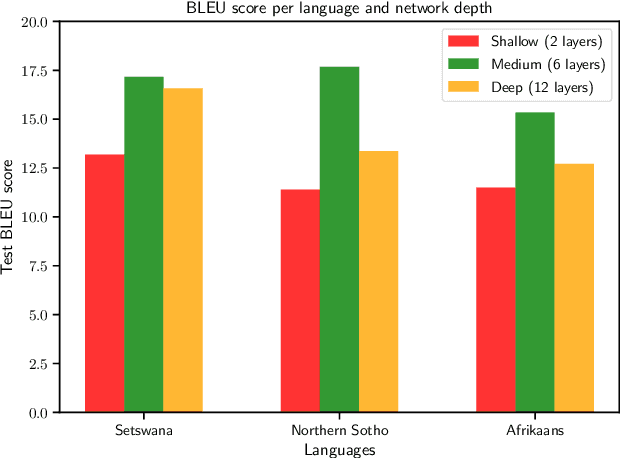



Transformers have shown great promise as an approach to Neural Machine Translation (NMT) for low-resource languages. However, at the same time, transformer models remain difficult to optimize and require careful tuning of hyper-parameters to be useful in this setting. Many NMT toolkits come with a set of default hyper-parameters, which researchers and practitioners often adopt for the sake of convenience and avoiding tuning. These configurations, however, have been optimized for large-scale machine translation data sets with several millions of parallel sentences for European languages like English and French. In this work, we find that the current trend in the field to use very large models is detrimental for low-resource languages, since it makes training more difficult and hurts overall performance, confirming previous observations. We see our work as complementary to the Masakhane project ("Masakhane" means "We Build Together" in isiZulu.) In this spirit, low-resource NMT systems are now being built by the community who needs them the most. However, many in the community still have very limited access to the type of computational resources required for building extremely large models promoted by industrial research. Therefore, by showing that transformer models perform well (and often best) at low-to-moderate depth, we hope to convince fellow researchers to devote less computational resources, as well as time, to exploring overly large models during the development of these systems.