Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-line learning dynamics of ReLU neural networks using statistical physics techniques
Paper and Code
Mar 18, 2019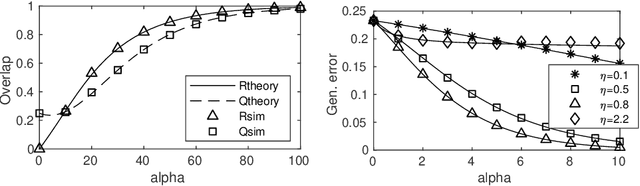

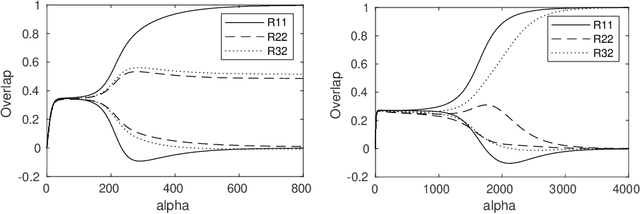

We introduce exact macroscopic on-line learning dynamics of two-layer neural networks with ReLU units in the form of a system of differential equations, using techniques borrowed from statistical physics. For the first experiments, numerical solutions reveal similar behavior compared to sigmoidal activation researched in earlier work. In these experiments the theoretical results show good correspondence with simulations. In ove-rrealizable and unrealizable learning scenarios, the learning behavior of ReLU networks shows distinctive characteristics compared to sigmoidal networks.
* Accepted contribution: ESANN 2019, 6 pages European Symposium on
Artificial Neural Networks, Computational Intelligence and Machine Learning
2019
View paper on