 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Learning and Enforcing Latent Assessment Models using Binary Feedback from Human Auditors Regarding Black-Box Classifiers
Paper and Code
Feb 16, 2022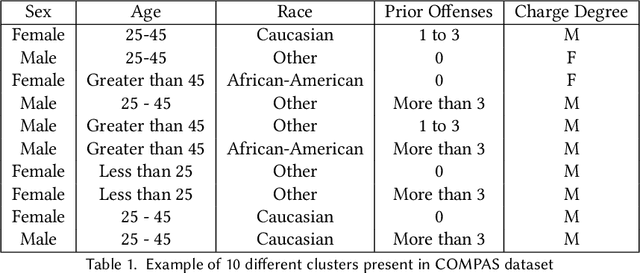
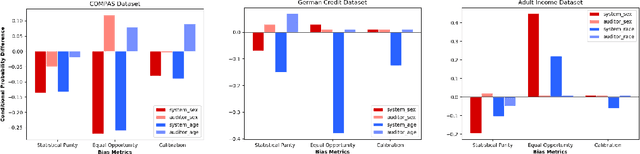
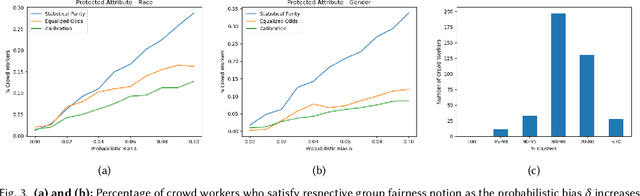
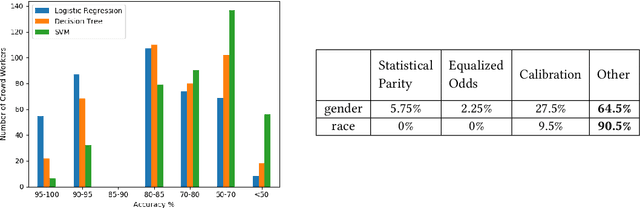
Algorithmic fairness literature presents numerous mathematical notions and metrics, and also points to a tradeoff between them while satisficing some or all of them simultaneously. Furthermore, the contextual nature of fairness notions makes it difficult to automate bias evaluation in diverse algorithmic systems. Therefore, in this paper, we propose a novel model called latent assessment model (LAM) to characterize binary feedback provided by human auditors, by assuming that the auditor compares the classifier's output to his or her own intrinsic judgment for each input. We prove that individual and group fairness notions are guaranteed as long as the auditor's intrinsic judgments inherently satisfy the fairness notion at hand, and are relatively similar to the classifier's evaluations. We also demonstrate this relationship between LAM and traditional fairness notions on three well-known datasets, namely COMPAS, German credit and Adult Census Income datasets. Furthermore, we also derive the minimum number of feedback samples needed to obtain PAC learning guarantees to estimate LAM for black-box classifiers. These guarantees are also validated via training standard machine learning algorithms on real binary feedback elicited from 400 human auditors regarding COMPAS.