 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Hard Exploration for Reinforcement Learning: a Case Study in Pommerman
Paper and Code


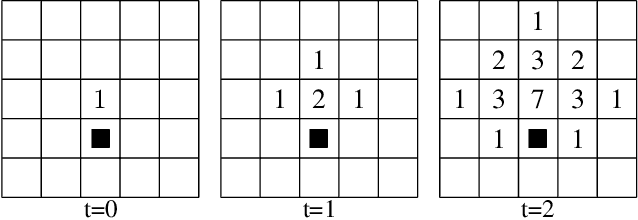
How to best explore in domains with sparse, delayed, and deceptive rewards is an important open problem for reinforcement learning (RL). This paper considers one such domain, the recently-proposed multi-agent benchmark of Pommerman. This domain is very challenging for RL --- past work has shown that model-free RL algorithms fail to achieve significant learning without artificially reducing the environment's complexity. In this paper, we illuminate reasons behind this failure by providing a thorough analysis on the hardness of random exploration in Pommerman. While model-free random exploration is typically futile, we develop a model-based automatic reasoning module that can be used for safer exploration by pruning actions that will surely lead the agent to death. We empirically demonstrate that this module can significantly improve learning.