 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Consistency of Compressive Spectral Clustering
Paper and Code
May 29, 2018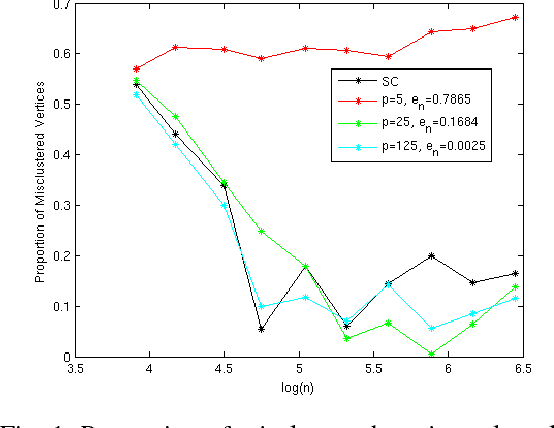

Spectral clustering is one of the most popular methods for community detection in graphs. A key step in spectral clustering algorithms is the eigen decomposition of the $n{\times}n$ graph Laplacian matrix to extract its $k$ leading eigenvectors, where $k$ is the desired number of clusters among $n$ objects. This is prohibitively complex to implement for very large datasets. However, it has recently been shown that it is possible to bypass the eigen decomposition by computing an approximate spectral embedding through graph filtering of random signals. In this paper, we analyze the working of spectral clustering performed via graph filtering on the stochastic block model. Specifically, we characterize the effects of sparsity, dimensionality and filter approximation error on the consistency of the algorithm in recovering planted clusters.