 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Anytime Learning at Macroscale
Paper and Code
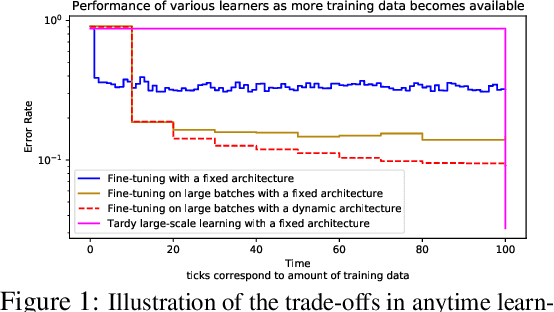
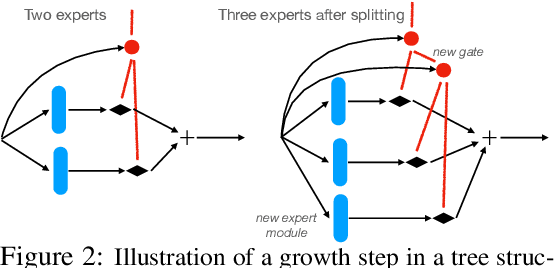
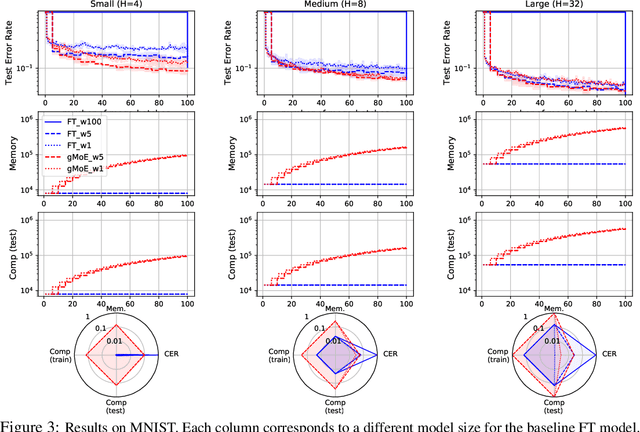
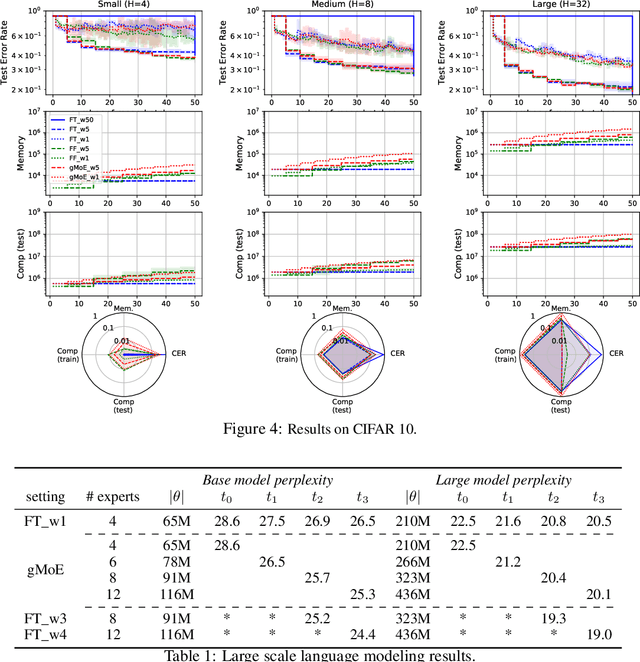
Classical machine learning frameworks assume access to a possibly large dataset in order to train a predictive model. In many practical applications however, data does not arrive all at once, but in batches over time. This creates a natural trade-off between accuracy of a model and time to obtain such a model. A greedy predictor could produce non-trivial predictions by immediately training on batches as soon as these become available but, it may also make sub-optimal use of future data. On the other hand, a tardy predictor could wait for a long time to aggregate several batches into a larger dataset, but ultimately deliver a much better performance. In this work, we consider such a streaming learning setting, which we dub {\em anytime learning at macroscale} (ALMA). It is an instance of anytime learning applied not at the level of a single chunk of data, but at the level of the entire sequence of large batches. We first formalize this learning setting, we then introduce metrics to assess how well learners perform on the given task for a given memory and compute budget, and finally we test several baseline approaches on standard benchmarks repurposed for anytime learning at macroscale. The general finding is that bigger models always generalize better. In particular, it is important to grow model capacity over time if the initial model is relatively small. Moreover, updating the model at an intermediate rate strikes the best trade off between accuracy and time to obtain a useful predictor.