 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOh My Mistake!: Toward Realistic Dialogue State Tracking including Turnback Utterances
Paper and Code
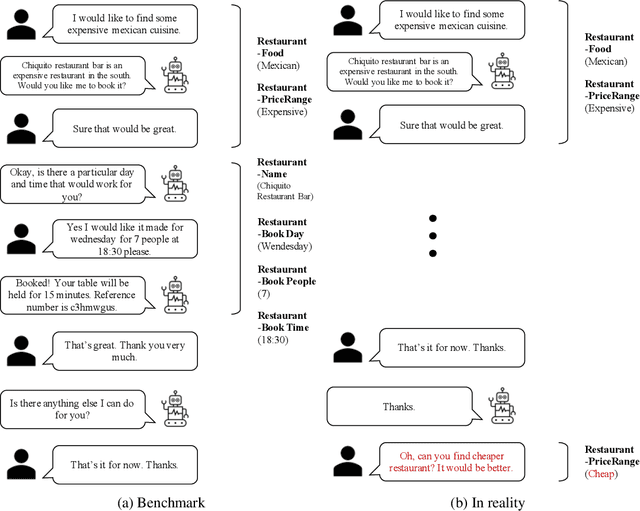
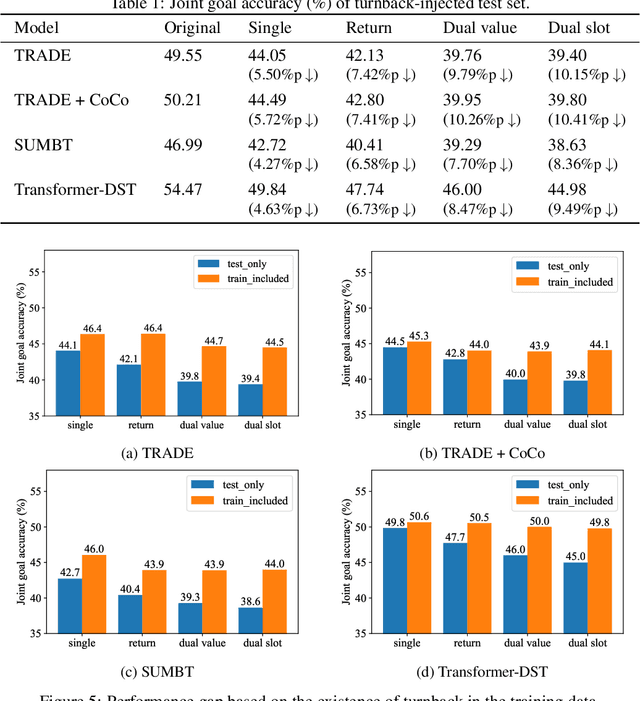

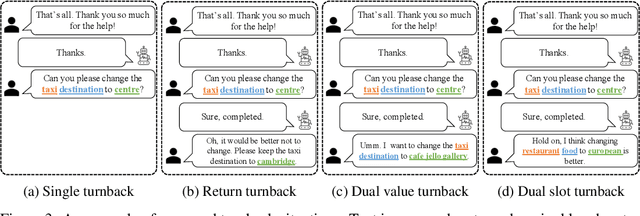
The primary purpose of dialogue state tracking (DST), a critical component of an end-to-end conversational system, is to build a model that responds well to real-world situations. Although we often change our minds during ordinary conversations, current benchmark datasets do not adequately reflect such occurrences and instead consist of over-simplified conversations, in which no one changes their mind during a conversation. As the main question inspiring the present study,``Are current benchmark datasets sufficiently diverse to handle casual conversations in which one changes their mind?'' We found that the answer is ``No'' because simply injecting template-based turnback utterances significantly degrades the DST model performance. The test joint goal accuracy on the MultiWOZ decreased by over 5\%p when the simplest form of turnback utterance was injected. Moreover, the performance degeneration worsens when facing more complicated turnback situations. However, we also observed that the performance rebounds when a turnback is appropriately included in the training dataset, implying that the problem is not with the DST models but rather with the construction of the benchmark dataset.