 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Text-Independent Writer Identification based on word level data
Paper and Code
Feb 21, 2022
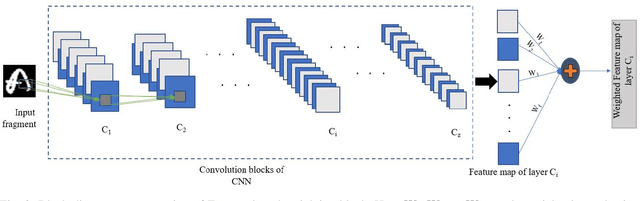


This paper proposes a novel scheme to identify the authorship of a document based on handwritten input word images of an individual. Our approach is text-independent and does not place any restrictions on the size of the input word images under consideration. To begin with, we employ the SIFT algorithm to extract multiple key points at various levels of abstraction (comprising allograph, character, or combination of characters). These key points are then passed through a trained CNN network to generate feature maps corresponding to a convolution layer. However, owing to the scale corresponding to the SIFT key points, the size of a generated feature map may differ. As an alleviation to this issue, the histogram of gradients is applied on the feature map to produce a fixed representation. Typically, in a CNN, the number of filters of each convolution block increase depending on the depth of the network. Thus, extracting histogram features for each of the convolution feature map increase the dimension as well as the computational load. To address this aspect, we use an entropy-based method to learn the weights of the feature maps of a particular CNN layer during the training phase of our algorithm. The efficacy of our proposed system has been demonstrated on two publicly available databases namely CVL and IAM. We empirically show that the results obtained are promising when compared with previous works.