 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Meta Reinforcement Learning
Paper and Code
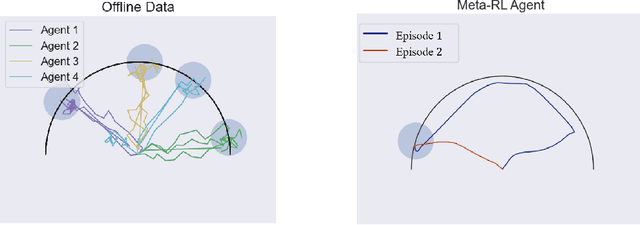

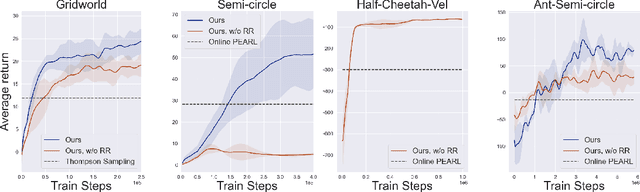

Consider the following problem, which we term Offline Meta Reinforcement Learning (OMRL): given the complete training histories of $N$ conventional RL agents, trained on $N$ different tasks, design a learning agent that can quickly maximize reward in a new, unseen task from the same task distribution. In particular, while each conventional RL agent explored and exploited its own different task, the OMRL agent must identify regularities in the data that lead to effective exploration/exploitation in the unseen task. To solve OMRL, we take a Bayesian RL (BRL) view, and seek to learn a Bayes-optimal policy from the offline data. We extend the recently proposed VariBAD BRL algorithm to the off-policy setting, and demonstrate learning of Bayes-optimal exploration strategies from offline data using deep neural networks. Furthermore, when applied to the online meta-RL setting (agent simultaneously collects data and improves its meta-RL policy), our method is significantly more sample efficient than the conventional VariBAD.