 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOdds-Ratio Thompson Sampling to Control for Time-Varying Effect
Paper and Code
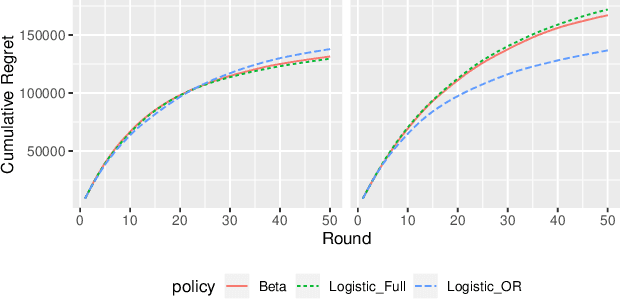
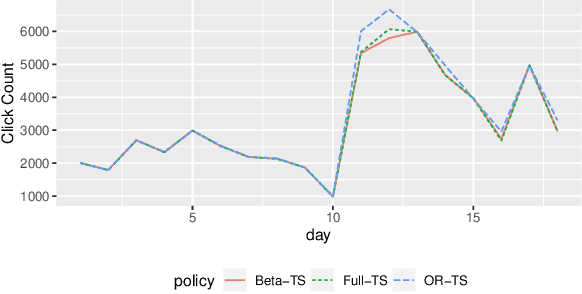
Multi-armed bandit methods have been used for dynamic experiments particularly in online services. Among the methods, thompson sampling is widely used because it is simple but shows desirable performance. Many thompson sampling methods for binary rewards use logistic model that is written in a specific parameterization. In this study, we reparameterize logistic model with odds ratio parameters. This shows that thompson sampling can be used with subset of parameters. Based on this finding, we propose a novel method, "Odds-ratio thompson sampling", which is expected to work robust to time-varying effect. Use of the proposed method in continuous experiment is described with discussing a desirable property of the method. In simulation studies, the novel method works robust to temporal background effect, while the loss of performance was only marginal in case with no such effect. Finally, using dataset from real service, we showed that the novel method would gain greater rewards in practical environment.