 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObstacle Avoidance for Robotic Manipulator in Joint Space via Improved Proximal Policy Optimization
Paper and Code
Oct 03, 2022
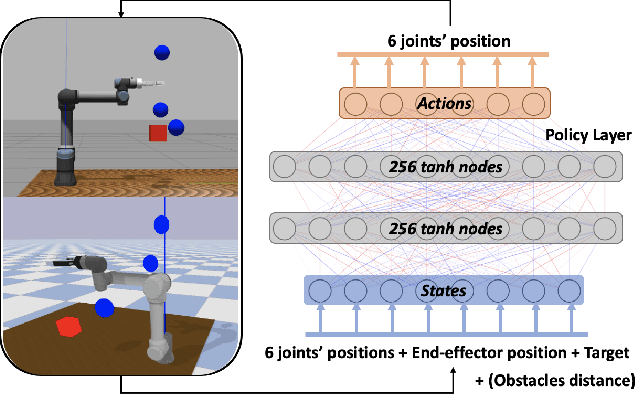
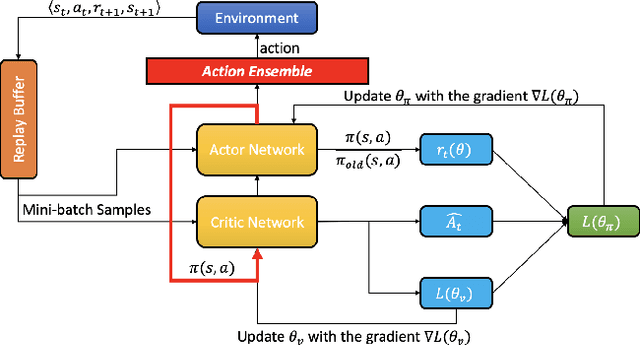
Reaching tasks with random targets and obstacles can still be challenging when the robotic arm is operating in unstructured environments. In contrast to traditional model-based methods, model-free reinforcement learning methods do not require complex inverse kinematics or dynamics equations to be calculated. In this paper, we train a deep neural network via an improved Proximal Policy Optimization (PPO) algorithm, which aims to map from task space to joint space for a 6-DoF manipulator. In particular, we modify the original PPO and design an effective representation for environmental inputs and outputs to train the robot faster in a larger workspace. Firstly, a type of action ensemble is adopted to improve output efficiency. Secondly, the policy is designed to join in value function updates directly. Finally, the distance between obstacles and links of the manipulator is calculated based on a geometry method as part of the representation of states. Since training such a task in real-robot is time-consuming and strenuous, we develop a simulation environment to train the model. We choose Gazebo as our first simulation environment since it often produces a smaller Sim-to-Real gap than other simulators. However, the training process in Gazebo is time-consuming and takes a long time. Therefore, to address this limitation, we propose a Sim-to-Sim method to reduce the training time significantly. The trained model is finally used in a real-robot setup without fine-tuning. Experimental results showed that using our method, the robot was capable of tracking a single target or reaching multiple targets in unstructured environments.