 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjectness-Aware One-Shot Semantic Segmentation
Paper and Code

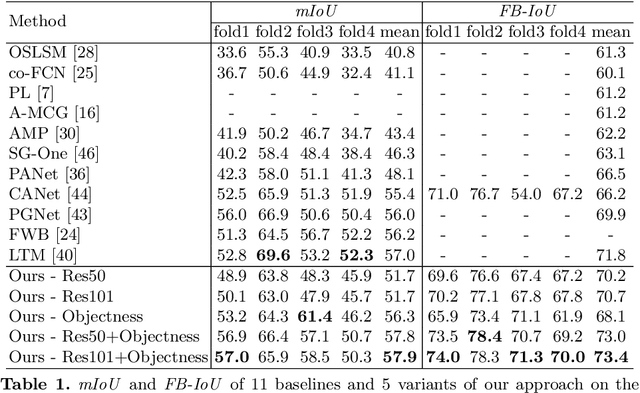
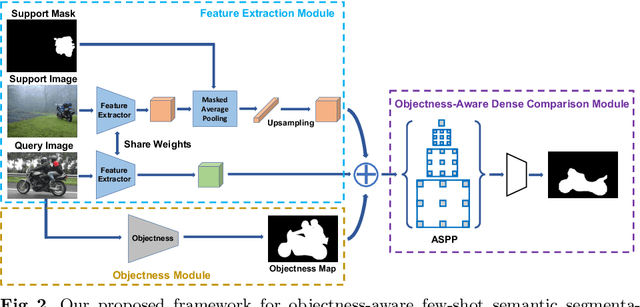

While deep convolutional neural networks have led to great progress in image semantic segmentation, they typically require collecting a large number of densely-annotated images for training. Moreover, once trained, the model can only make predictions in a pre-defined set of categories. Therefore, few-shot image semantic segmentation has been explored to learn to segment from only a few annotated examples. In this paper, we tackle the challenging one-shot semantic segmentation problem by taking advantage of objectness. In order to capture prior knowledge of object and background, we first train an objectness segmentation module which generalizes well to unseen categories. Then we use the objectness module to predict the objects present in the query image, and train an objectness-aware few-shot segmentation model that takes advantage of both the object information and limited annotations of the unseen category to perform segmentation in the query image. Our method achieves a mIoU score of 57.9% and 22.6% given only one annotated example of an unseen category in PASCAL-5i and COCO-20i, outperforming related baselines overall.