 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Skeleton Extraction in Natural Images by Fusing Scale-associated Deep Side Outputs
Paper and Code
Apr 06, 2016
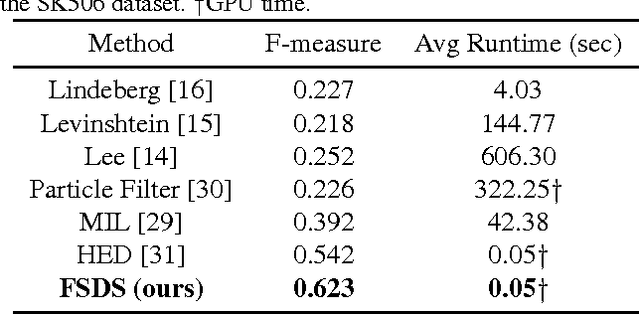
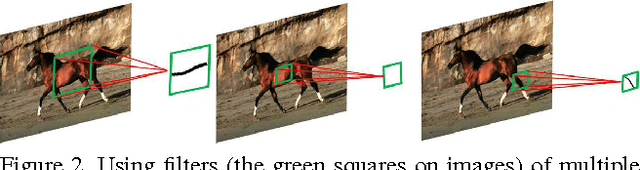

Object skeleton is a useful cue for object detection, complementary to the object contour, as it provides a structural representation to describe the relationship among object parts. While object skeleton extraction in natural images is a very challenging problem, as it requires the extractor to be able to capture both local and global image context to determine the intrinsic scale of each skeleton pixel. Existing methods rely on per-pixel based multi-scale feature computation, which results in difficult modeling and high time consumption. In this paper, we present a fully convolutional network with multiple scale-associated side outputs to address this problem. By observing the relationship between the receptive field sizes of the sequential stages in the network and the skeleton scales they can capture, we introduce a scale-associated side output to each stage. We impose supervision to different stages by guiding the scale-associated side outputs toward groundtruth skeletons of different scales. The responses of the multiple scale-associated side outputs are then fused in a scale-specific way to localize skeleton pixels with multiple scales effectively. Our method achieves promising results on two skeleton extraction datasets, and significantly outperforms other competitors.