 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNullaNet: Training Deep Neural Networks for Reduced-Memory-Access Inference
Paper and Code
Aug 27, 2018
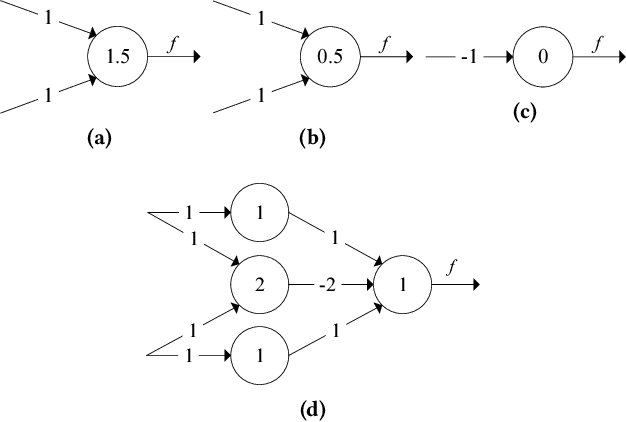
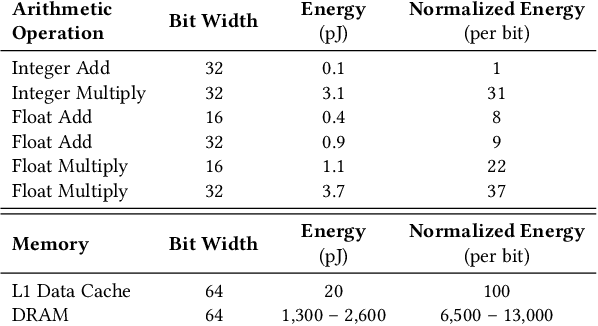
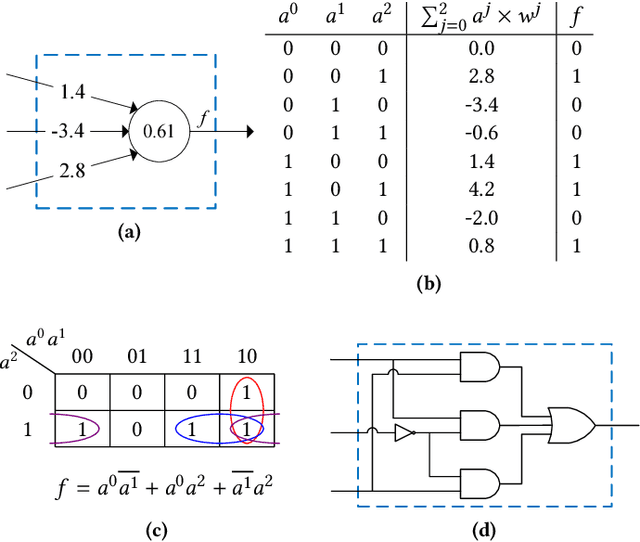
Deep neural networks have been successfully deployed in a wide variety of applications including computer vision and speech recognition. However, computational and storage complexity of these models has forced the majority of computations to be performed on high-end computing platforms or on the cloud. To cope with computational and storage complexity of these models, this paper presents a training method that enables a radically different approach for realization of deep neural networks through Boolean logic minimization. The aforementioned realization completely removes the energy-hungry step of accessing memory for obtaining model parameters, consumes about two orders of magnitude fewer computing resources compared to realizations that use floatingpoint operations, and has a substantially lower latency.