 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovelty Detection and Learning from Extremely Weak Supervision
Paper and Code
Nov 01, 2019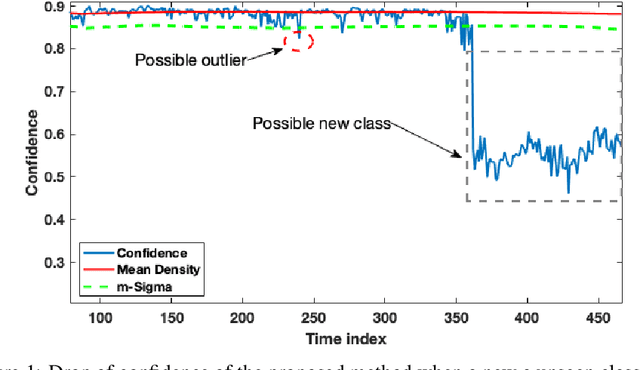
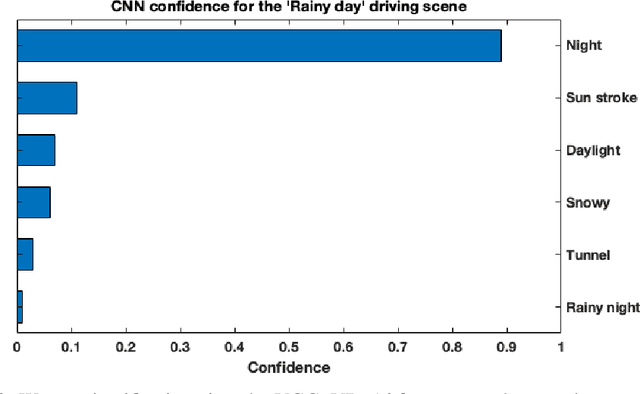
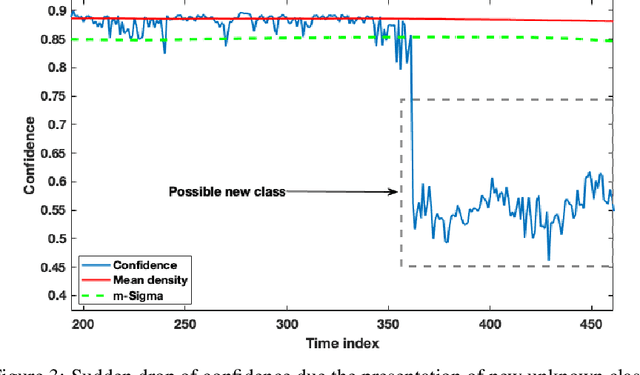

In this paper we offer a method and algorithm, which make possible fully autonomous (unsupervised) detection of new classes, and learning following a very parsimonious training priming (few labeled data samples only). Moreover, new unknown classes may appear at a later stage and the proposed xClass method and algorithm are able to successfully discover this and learn from the data autonomously. Furthermore, the features (inputs to the classifier) are automatically sub-selected by the algorithm based on the accumulated data density per feature per class. As a result, a highly efficient, lean, human-understandable, autonomously self-learning model (which only needs an extremely parsimonious priming) emerges from the data. To validate our proposal we tested it on two challenging problems, including imbalanced Caltech-101 data set and iRoads dataset. Not only we achieved higher precision, but, more significantly, we only used a single class beforehand, while other methods used all the available classes) and we generated interpretable models with smaller number of features used, through extremely weak and weak supervision.