 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalized Web Distance and Word Similarity
Paper and Code
May 25, 2009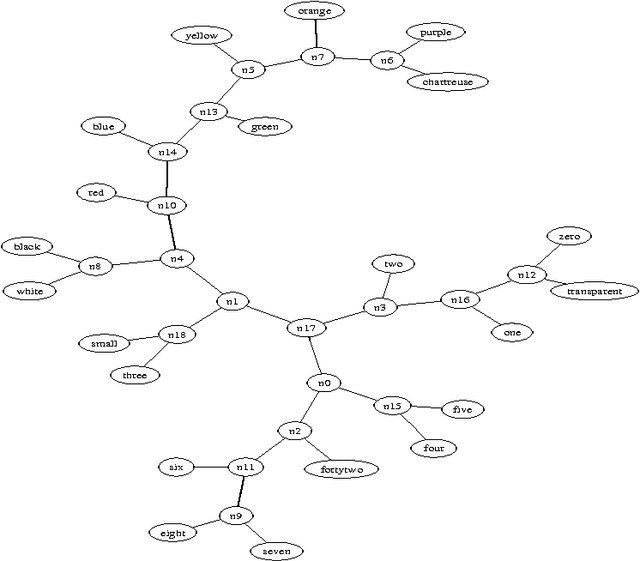
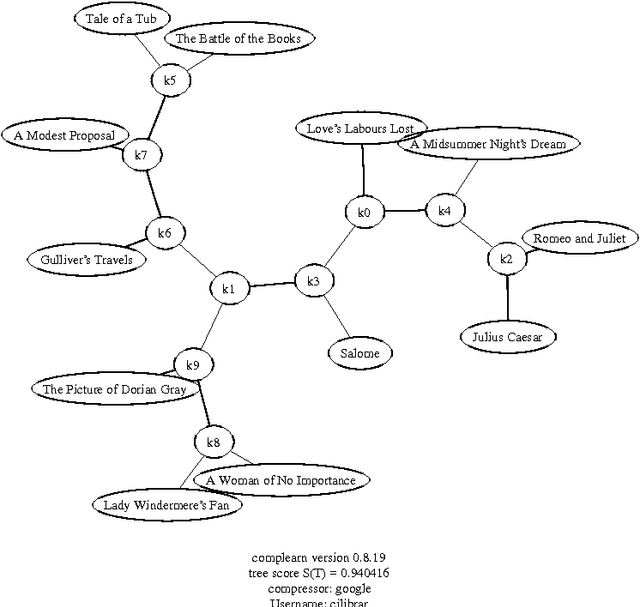

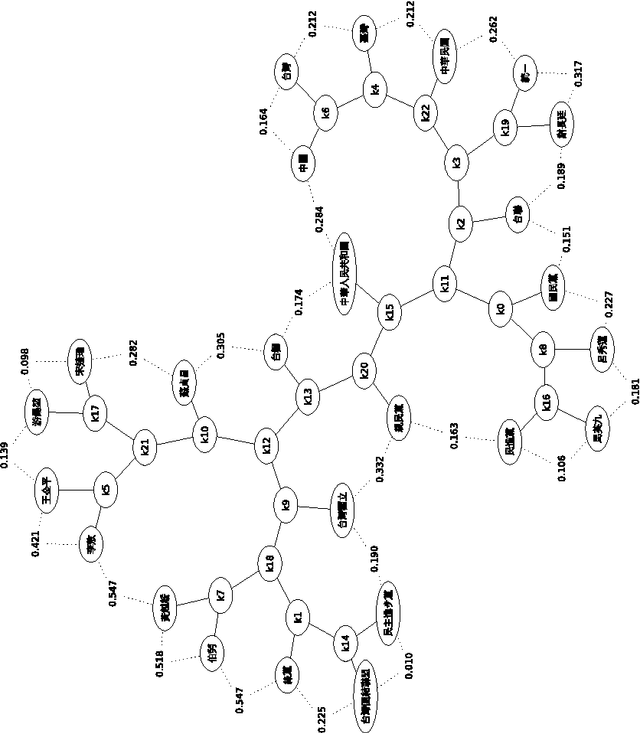
There is a great deal of work in cognitive psychology, linguistics, and computer science, about using word (or phrase) frequencies in context in text corpora to develop measures for word similarity or word association, going back to at least the 1960s. The goal of this chapter is to introduce the normalizedis a general way to tap the amorphous low-grade knowledge available for free on the Internet, typed in by local users aiming at personal gratification of diverse objectives, and yet globally achieving what is effectively the largest semantic electronic database in the world. Moreover, this database is available for all by using any search engine that can return aggregate page-count estimates for a large range of search-queries. In the paper introducing the NWD it was called `normalized Google distance (NGD),' but since Google doesn't allow computer searches anymore, we opt for the more neutral and descriptive NWD. web distance (NWD) method to determine similarity between words and phrases. It