 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalization of Neural Networks using Analytic Variance Propagation
Paper and Code
Mar 28, 2018
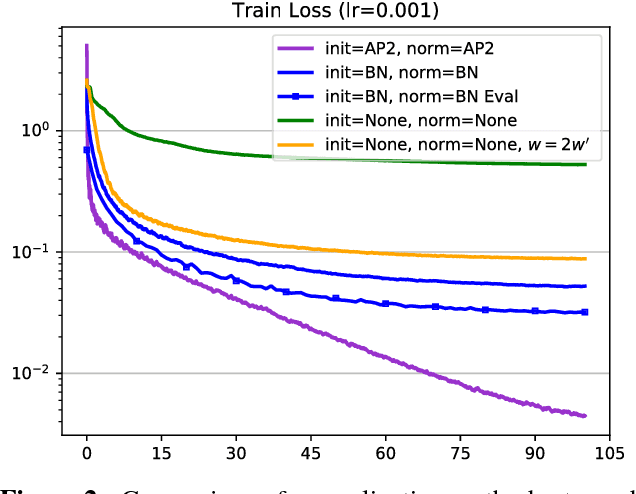


We address the problem of estimating statistics of hidden units in a neural network using a method of analytic moment propagation. These statistics are useful for approximate whitening of the inputs in front of saturating non-linearities such as a sigmoid function. This is important for initialization of training and for reducing the accumulated scale and bias dependencies (compensating covariate shift), which presumably eases the learning. In batch normalization, which is currently a very widely applied technique, sample estimates of statistics of hidden units over a batch are used. The proposed estimation uses an analytic propagation of mean and variance of the training set through the network. The result depends on the network structure and its current weights but not on the specific batch input. The estimates are suitable for initialization and normalization, efficient to compute and independent of the batch size. The experimental verification well supports these claims. However, the method does not share the generalization properties of BN, to which our experiments give some additional insight.