 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Detection of Anomalous Data Streams
Paper and Code
Dec 14, 2016


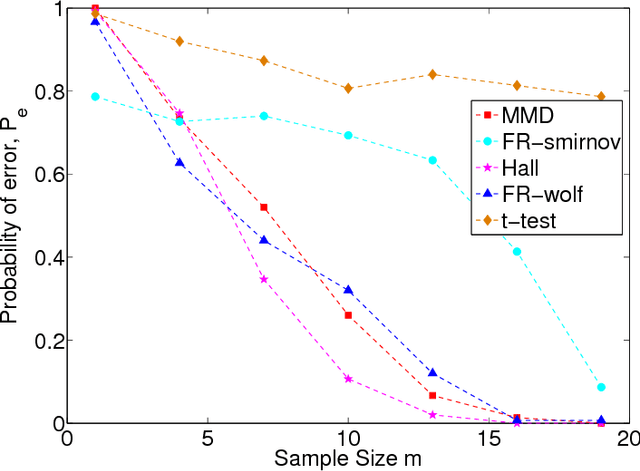
A nonparametric anomalous hypothesis testing problem is investigated, in which there are totally n sequences with s anomalous sequences to be detected. Each typical sequence contains m independent and identically distributed (i.i.d.) samples drawn from a distribution p, whereas each anomalous sequence contains m i.i.d. samples drawn from a distribution q that is distinct from p. The distributions p and q are assumed to be unknown in advance. Distribution-free tests are constructed using maximum mean discrepancy as the metric, which is based on mean embeddings of distributions into a reproducing kernel Hilbert space. The probability of error is bounded as a function of the sample size m, the number s of anomalous sequences and the number n of sequences. It is then shown that with s known, the constructed test is exponentially consistent if m is greater than a constant factor of log n, for any p and q, whereas with s unknown, m should has an order strictly greater than log n. Furthermore, it is shown that no test can be consistent for arbitrary p and q if m is less than a constant factor of log n, thus the order-level optimality of the proposed test is established. Numerical results are provided to demonstrate that our tests outperform (or perform as well as) the tests based on other competitive approaches under various cases.