 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonasymptotic Guarantees for Low-Rank Matrix Recovery with Generative Priors
Paper and Code
Jun 14, 2020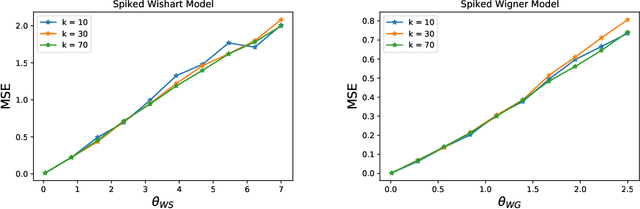
Many problems in statistics and machine learning require the reconstruction of a low-rank signal matrix from noisy data. Enforcing additional prior information on the low-rank component is often key to guaranteeing good recovery performance. One such prior on the low-rank component is sparsity, giving rise to the sparse principal component analysis problem. Unfortunately, this problem suffers from a computational-to-statistical gap, which may be fundamental. In this work, we study an alternative prior where the low-rank component is in the range of a trained generative network. We provide a non-asymptotic analysis with optimal sample complexity, up to logarithmic factors, for low-rank matrix recovery under an expansive-Gaussian network prior. Specifically, we establish a favorable global optimization landscape for a mean squared error optimization, provided the number of samples is on the order of the dimensionality of the input to the generative model. As a result, we establish that generative priors have no computational-to-statistical gap for structured low-rank matrix recovery in the finite data, nonasymptotic regime. We present this analysis in the case of both the Wishart and Wigner spiked matrix models.