 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Parametric Transformation Networks
Paper and Code
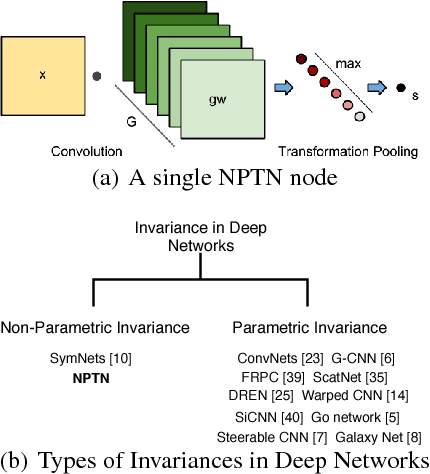

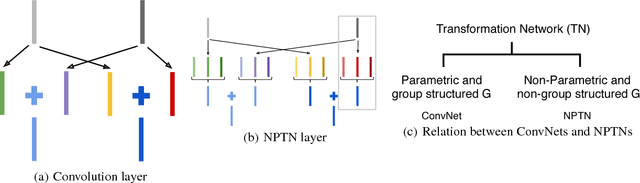
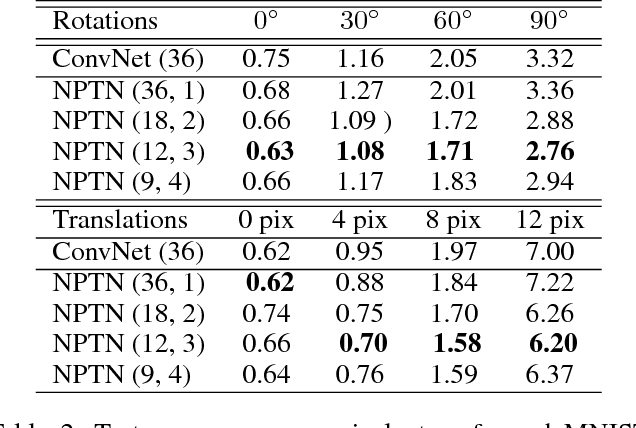
ConvNets, through their architecture, only enforce invariance to translation. In this paper, we introduce a new class of deep convolutional architectures called Non-Parametric Transformation Networks (NPTNs) which can learn \textit{general} invariances and symmetries directly from data. NPTNs are a natural generalization of ConvNets and can be optimized directly using gradient descent. Unlike almost all previous works in deep architectures, they make no assumption regarding the structure of the invariances present in the data and in that aspect are flexible and powerful. We also model ConvNets and NPTNs under a unified framework called Transformation Networks (TN), which yields a better understanding of the connection between the two. We demonstrate the efficacy of NPTNs on data such as MNIST with extreme transformations and CIFAR10 where they outperform baselines, and further outperform several recent algorithms on ETH-80. They do so while having the same number of parameters. We also show that they are more effective than ConvNets in modelling symmetries and invariances from data, without the explicit knowledge of the added arbitrary nuisance transformations. Finally, we replace ConvNets with NPTNs within Capsule Networks and show that this enables Capsule Nets to perform even better.