 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-intrusive Load Monitoring based on Self-supervised Learning
Paper and Code
Oct 09, 2022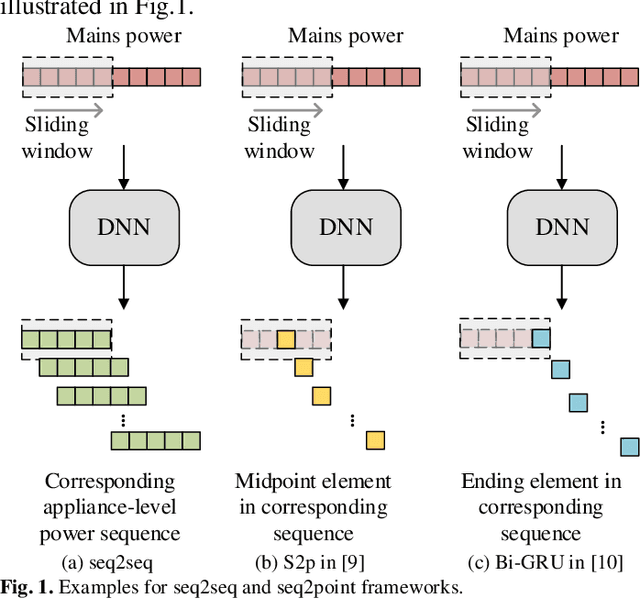
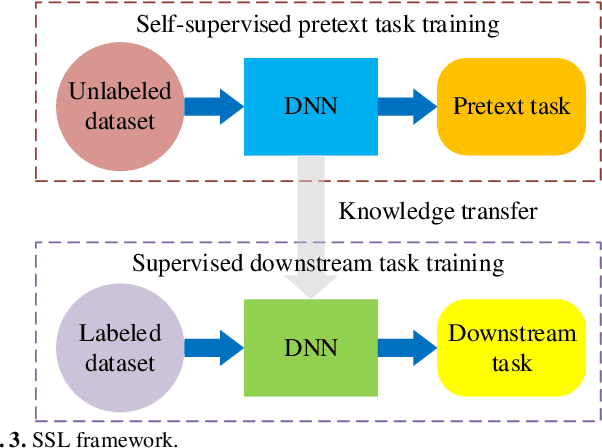
Deep learning models for non-intrusive load monitoring (NILM) tend to require a large amount of labeled data for training. However, it is difficult to generalize the trained models to unseen sites due to different load characteristics and operating patterns of appliances between data sets. For addressing such problems, self-supervised learning (SSL) is proposed in this paper, where labeled appliance-level data from the target data set or house is not required. Initially, only the aggregate power readings from target data set are required to pre-train a general network via a self-supervised pretext task to map aggregate power sequences to derived representatives. Then, supervised downstream tasks are carried out for each appliance category to fine-tune the pre-trained network, where the features learned in the pretext task are transferred. Utilizing labeled source data sets enables the downstream tasks to learn how each load is disaggregated, by mapping the aggregate to labels. Finally, the fine-tuned network is applied to load disaggregation for the target sites. For validation, multiple experimental cases are designed based on three publicly accessible REDD, UK-DALE, and REFIT data sets. Besides, state-of-the-art neural networks are employed to perform NILM task in the experiments. Based on the NILM results in various cases, SSL generally outperforms zero-shot learning in improving load disaggregation performance without any sub-metering data from the target data sets.