 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Comparative Fairness for Human-Auditing and Its Relation to Traditional Fairness Notions
Paper and Code
Jun 29, 2021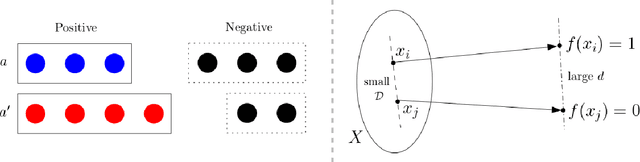
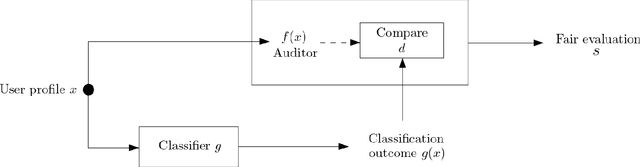
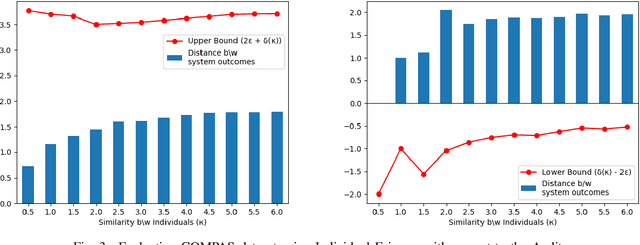

Bias evaluation in machine-learning based services (MLS) based on traditional algorithmic fairness notions that rely on comparative principles is practically difficult, making it necessary to rely on human auditor feedback. However, in spite of taking rigorous training on various comparative fairness notions, human auditors are known to disagree on various aspects of fairness notions in practice, making it difficult to collect reliable feedback. This paper offers a paradigm shift to the domain of algorithmic fairness via proposing a new fairness notion based on the principle of non-comparative justice. In contrary to traditional fairness notions where the outcomes of two individuals/groups are compared, our proposed notion compares the MLS' outcome with a desired outcome for each input. This desired outcome naturally describes a human auditor's expectation, and can be easily used to evaluate MLS on crowd-auditing platforms. We show that any MLS can be deemed fair from the perspective of comparative fairness (be it in terms of individual fairness, statistical parity, equal opportunity or calibration) if it is non-comparatively fair with respect to a fair auditor. We also show that the converse holds true in the context of individual fairness. Given that such an evaluation relies on the trustworthiness of the auditor, we also present an approach to identify fair and reliable auditors by estimating their biases with respect to a given set of sensitive attributes, as well as quantify the uncertainty in the estimation of biases within a given MLS. Furthermore, all of the above results are also validated on COMPAS, German credit and Adult Census Income datasets.