 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-binary deep transfer learning for imageclassification
Paper and Code
Jul 19, 2021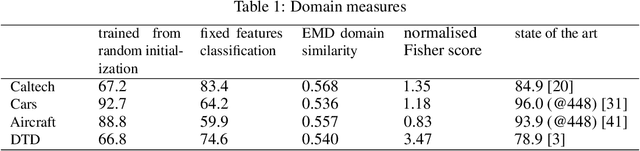



The current standard for a variety of computer vision tasks using smaller numbers of labelled training examples is to fine-tune from weights pre-trained on a large image classification dataset such as ImageNet. The application of transfer learning and transfer learning methods tends to be rigidly binary. A model is either pre-trained or not pre-trained. Pre-training a model either increases performance or decreases it, the latter being defined as negative transfer. Application of L2-SP regularisation that decays the weights towards their pre-trained values is either applied or all weights are decayed towards 0. This paper re-examines these assumptions. Our recommendations are based on extensive empirical evaluation that demonstrate the application of a non-binary approach to achieve optimal results. (1) Achieving best performance on each individual dataset requires careful adjustment of various transfer learning hyperparameters not usually considered, including number of layers to transfer, different learning rates for different layers and different combinations of L2SP and L2 regularization. (2) Best practice can be achieved using a number of measures of how well the pre-trained weights fit the target dataset to guide optimal hyperparameters. We present methods for non-binary transfer learning including combining L2SP and L2 regularization and performing non-traditional fine-tuning hyperparameter searches. Finally we suggest heuristics for determining the optimal transfer learning hyperparameters. The benefits of using a non-binary approach are supported by final results that come close to or exceed state of the art performance on a variety of tasks that have traditionally been more difficult for transfer learning.