 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy Ostracods: A Fine-Grained, Imbalanced Real-World Dataset for Benchmarking Robust Machine Learning and Label Correction Methods
Paper and Code
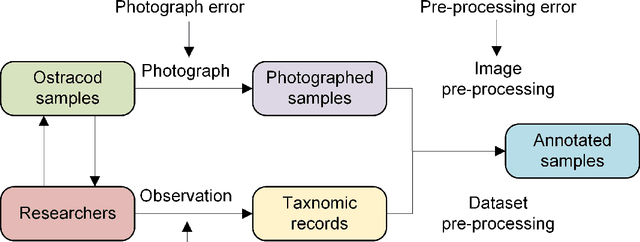
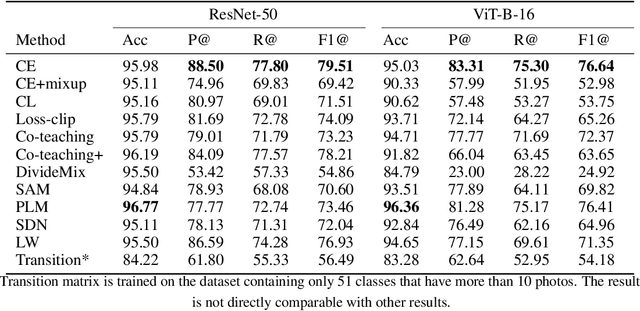

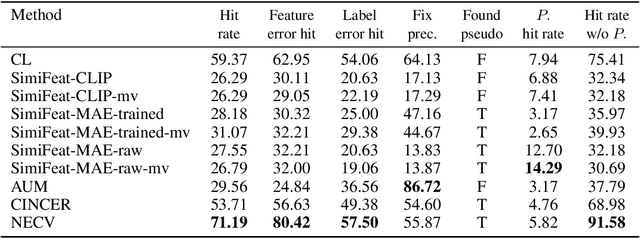
We present the Noisy Ostracods, a noisy dataset for genus and species classification of crustacean ostracods with specialists' annotations. Over the 71466 specimens collected, 5.58% of them are estimated to be noisy (possibly problematic) at genus level. The dataset is created to addressing a real-world challenge: creating a clean fine-grained taxonomy dataset. The Noisy Ostracods dataset has diverse noises from multiple sources. Firstly, the noise is open-set, including new classes discovered during curation that were not part of the original annotation. The dataset has pseudo-classes, where annotators misclassified samples that should belong to an existing class into a new pseudo-class. The Noisy Ostracods dataset is highly imbalanced with a imbalance factor $\rho$ = 22429. This presents a unique challenge for robust machine learning methods, as existing approaches have not been extensively evaluated on fine-grained classification tasks with such diverse real-world noise. Initial experiments using current robust learning techniques have not yielded significant performance improvements on the Noisy Ostracods dataset compared to cross-entropy training on the raw, noisy data. On the other hand, noise detection methods have underperformed in error hit rate compared to naive cross-validation ensembling for identifying problematic labels. These findings suggest that the fine-grained, imbalanced nature, and complex noise characteristics of the dataset present considerable challenges for existing noise-robust algorithms. By openly releasing the Noisy Ostracods dataset, our goal is to encourage further research into the development of noise-resilient machine learning methods capable of effectively handling diverse, real-world noise in fine-grained classification tasks. The dataset, along with its evaluation protocols, can be accessed at https://github.com/H-Jamieu/Noisy_ostracods.