 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext-Step Conditioned Deep Convolutional Neural Networks Improve Protein Secondary Structure Prediction
Paper and Code
Feb 13, 2017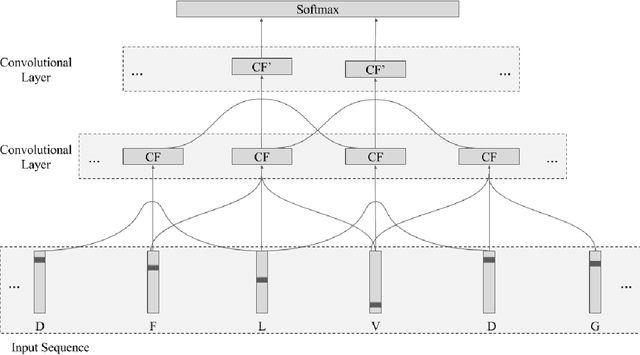
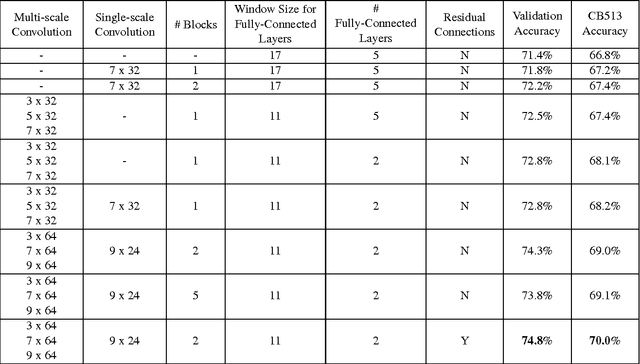
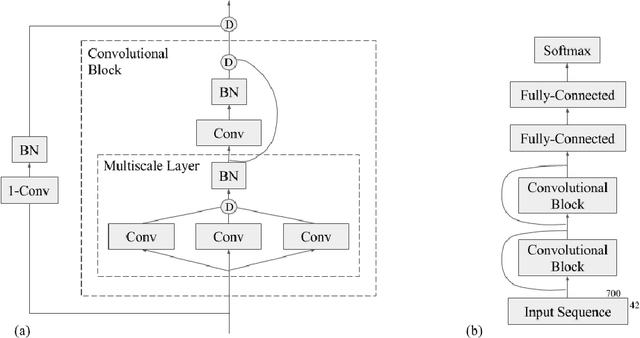
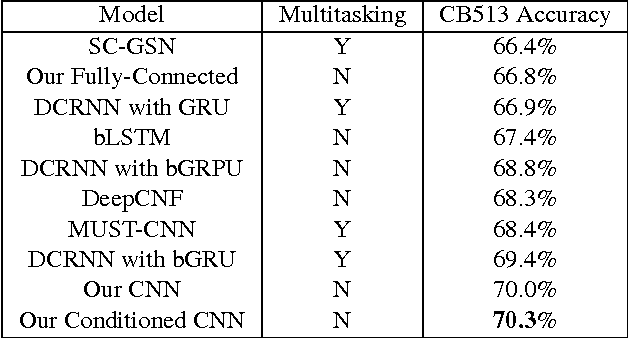
Recently developed deep learning techniques have significantly improved the accuracy of various speech and image recognition systems. In this paper we show how to adapt some of these techniques to create a novel chained convolutional architecture with next-step conditioning for improving performance on protein sequence prediction problems. We explore its value by demonstrating its ability to improve performance on eight-class secondary structure prediction. We first establish a state-of-the-art baseline by adapting recent advances in convolutional neural networks which were developed for vision tasks. This model achieves 70.0% per amino acid accuracy on the CB513 benchmark dataset without use of standard performance-boosting techniques such as ensembling or multitask learning. We then improve upon this state-of-the-art result using a novel chained prediction approach which frames the secondary structure prediction as a next-step prediction problem. This sequential model achieves 70.3% Q8 accuracy on CB513 with a single model; an ensemble of these models produces 71.4% Q8 accuracy on the same test set, improving upon the previous overall state of the art for the eight-class secondary structure problem. Our models are implemented using TensorFlow, an open-source machine learning software library available at TensorFlow.org; we aim to release the code for these experiments as part of the TensorFlow repository.