 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNewton: Gravitating Towards the Physical Limits of Crossbar Acceleration
Paper and Code
Mar 10, 2018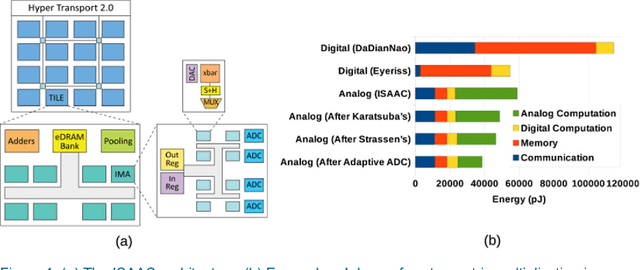
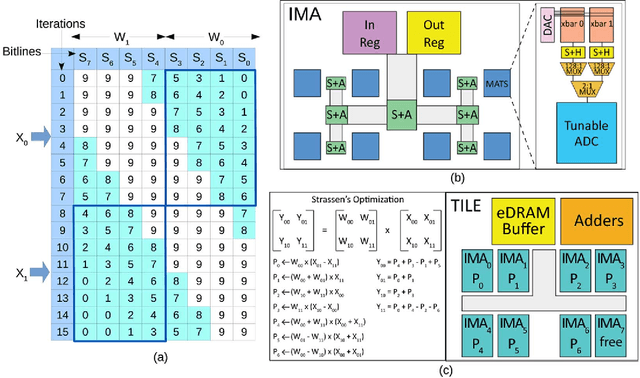
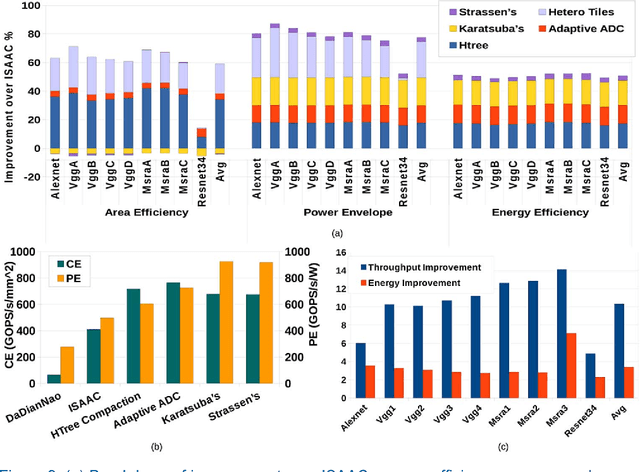
Many recent works have designed accelerators for Convolutional Neural Networks (CNNs). While digital accelerators have relied on near data processing, analog accelerators have further reduced data movement by performing in-situ computation. Recent works take advantage of highly parallel analog in-situ computation in memristor crossbars to accelerate the many vector-matrix multiplication operations in CNNs. However, these in-situ accelerators have two significant short-comings that we address in this work. First, the ADCs account for a large fraction of chip power and area. Second, these accelerators adopt a homogeneous design where every resource is provisioned for the worst case. By addressing both problems, the new architecture, Newton, moves closer to achieving optimal energy-per-neuron for crossbar accelerators. We introduce multiple new techniques that apply at different levels of the tile hierarchy. Two of the techniques leverage heterogeneity: one adapts ADC precision based on the requirements of every sub-computation (with zero impact on accuracy), and the other designs tiles customized for convolutions or classifiers. Two other techniques rely on divide-and-conquer numeric algorithms to reduce computations and ADC pressure. Finally, we place constraints on how a workload is mapped to tiles, thus helping reduce resource provisioning in tiles. For a wide range of CNN dataflows and structures, Newton achieves a 77% decrease in power, 51% improvement in energy efficiency, and 2.2x higher throughput/area, relative to the state-of-the-art ISAAC accelerator.