 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Ideas and Trends in Deep Multimodal Content Understanding: A Review
Paper and Code
Oct 16, 2020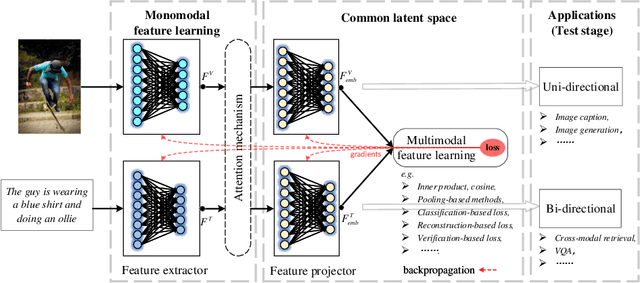

The focus of this survey is on the analysis of two modalities of multimodal deep learning: image and text. Unlike classic reviews of deep learning where monomodal image classifiers such as VGG, ResNet and Inception module are central topics, this paper will examine recent multimodal deep models and structures, including auto-encoders, generative adversarial nets and their variants. These models go beyond the simple image classifiers in which they can do uni-directional (e.g. image captioning, image generation) and bi-directional (e.g. cross-modal retrieval, visual question answering) multimodal tasks. Besides, we analyze two aspects of the challenge in terms of better content understanding in deep multimodal applications. We then introduce current ideas and trends in deep multimodal feature learning, such as feature embedding approaches and objective function design, which are crucial in overcoming the aforementioned challenges. Finally, we include several promising directions for future research.