 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-RAM Unit with Applications to Similarity Testing and Compression in Spiking Neural Networks
Paper and Code
Aug 21, 2017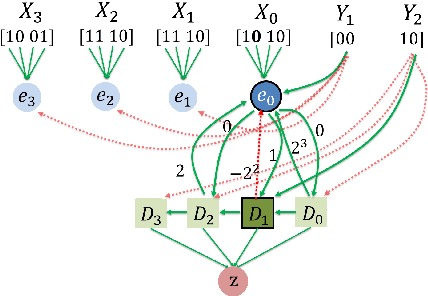

We study distributed algorithms implemented in a simplified biologically inspired model for stochastic spiking neural networks. We focus on tradeoffs between computation time and network complexity, along with the role of randomness in efficient neural computation. It is widely accepted that neural computation is inherently stochastic. In recent work, we explored how this stochasticity could be leveraged to solve the `winner-take-all' leader election task. Here, we focus on using randomness in neural algorithms for similarity testing and compression. In the most basic setting, given two $n$-length patterns of firing neurons, we wish to distinguish if the patterns are equal or $\epsilon$-far from equal. Randomization allows us to solve this task with a very compact network, using $O \left (\frac{\sqrt{n}\log n}{\epsilon}\right)$ auxiliary neurons, which is sublinear in the input size. At the heart of our solution is the design of a $t$-round neural random access memory, or indexing network, which we call a neuro-RAM. This module can be implemented with $O(n/t)$ auxiliary neurons and is useful in many applications beyond similarity testing. Using a VC dimension-based argument, we show that the tradeoff between runtime and network size in our neuro-RAM is nearly optimal. Our result has several implications -- since our neuro-RAM can be implemented with deterministic threshold gates, it shows that, in contrast to similarity testing, randomness does not provide significant computational advantages for this problem. It also establishes a separation between feedforward networks whose gates spike with sigmoidal probability functions, and well-studied deterministic sigmoidal networks, whose gates output real number sigmoidal values, and which can implement a neuro-RAM much more efficiently.