Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Variational Learning for Grounded Language Acquisition
Paper and Code
Jul 20, 2021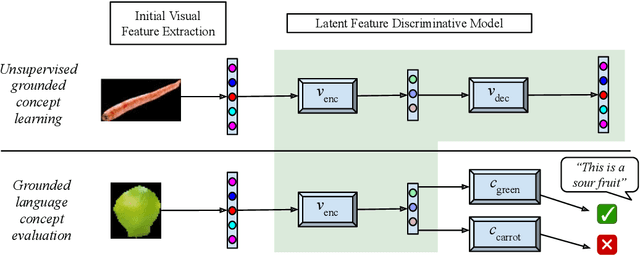



We propose a learning system in which language is grounded in visual percepts without specific pre-defined categories of terms. We present a unified generative method to acquire a shared semantic/visual embedding that enables the learning of language about a wide range of real-world objects. We evaluate the efficacy of this learning by predicting the semantics of objects and comparing the performance with neural and non-neural inputs. We show that this generative approach exhibits promising results in language grounding without pre-specifying visual categories under low resource settings. Our experiments demonstrate that this approach is generalizable to multilingual, highly varied datasets.
* 2021 30th IEEE International Conference on Robot and Human
Interactive Communication (RO-MAN)
View paper on