Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural networks adapting to datasets: learning network size and topology
Paper and Code
Jul 15, 2020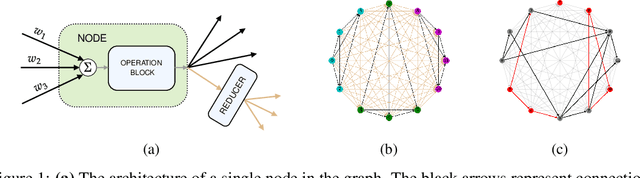
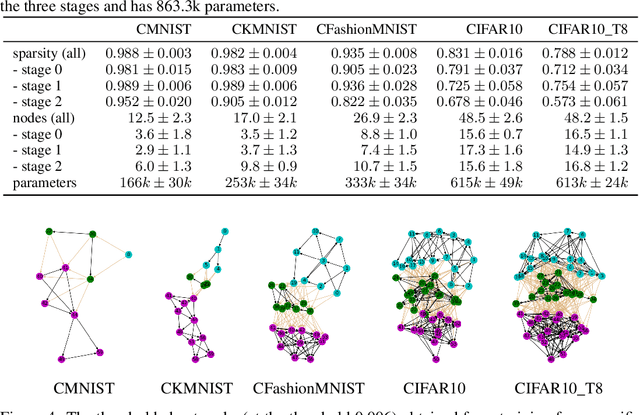
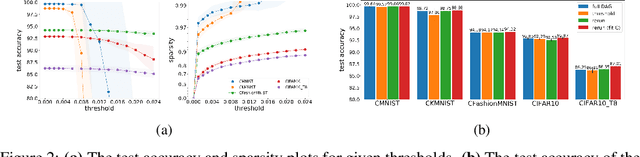
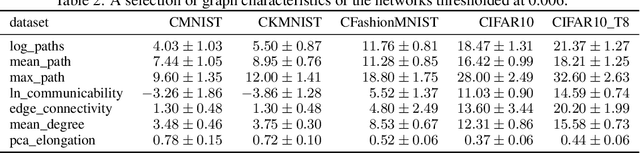
We introduce a flexible setup allowing for a neural network to learn both its size and topology during the course of a standard gradient-based training. The resulting network has the structure of a graph tailored to the particular learning task and dataset. The obtained networks can also be trained from scratch and achieve virtually identical performance. We explore the properties of the network architectures for a number of datasets of varying difficulty observing systematic regularities. The obtained graphs can be therefore understood as encoding nontrivial characteristics of the particular classification tasks.
* Fixed blank page
View paper on