 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural machine translation framework based cross-lingual document vector with distance constraint training
Paper and Code
Sep 04, 2018

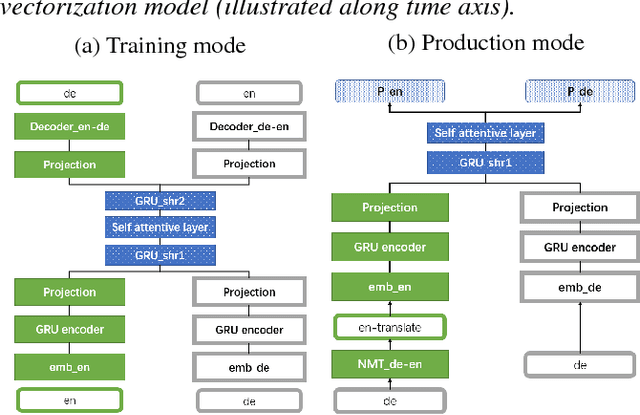

A universal cross-lingual representation of documents is very important for many natural language processing tasks. In this paper, we present a document vectorization method which can effectively create document vectors via self-attention mechanism using a neural machine translation (NMT) framework. The model used by our method can be trained with parallel corpora that are unrelated to the task at hand. During testing, our method will take a monolingual document and convert it into a "Neural machine Translation framework based crosslingual Document Vector with distance constraint training" (cNTDV). cNTDV is a follow-up study from our previous research on the neural machine translation framework based document vector. The cNTDV can produce the document vector from a forward-pass of the encoder with fast speed. Moreover, it is trained with a distance constraint, so that the document vector obtained from different language pair is always consistent with each other. In a cross-lingual document classification task, our cNTDV embeddings surpass the published state-of-the-art performance in the English-to-German classification test, and, to our best knowledge, it also achieves the second best performance in German-to-English classification test. Comparing to our previous research, it does not need a translator in the testing process, which makes the model faster and more convenient.