 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Language Modeling with Visual Features
Paper and Code
Mar 07, 2019
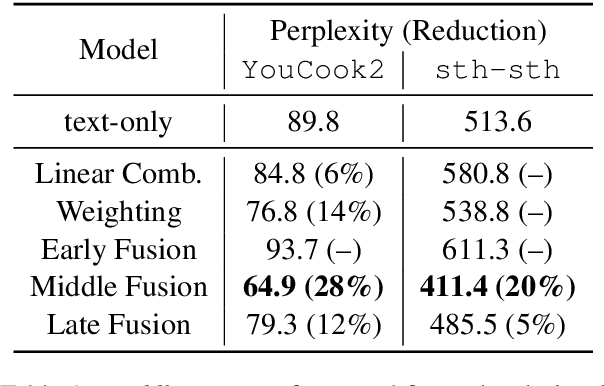
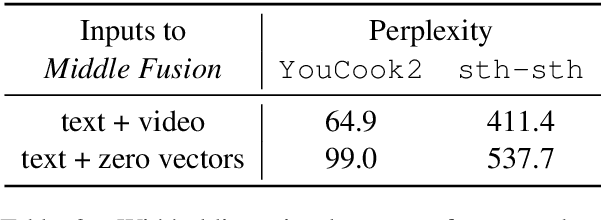
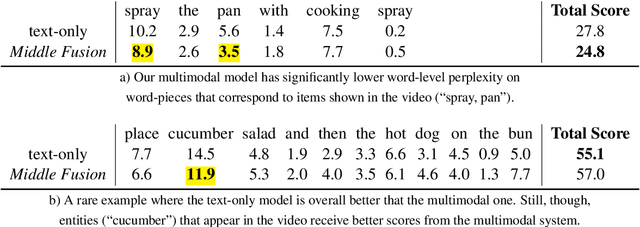
Multimodal language models attempt to incorporate non-linguistic features for the language modeling task. In this work, we extend a standard recurrent neural network (RNN) language model with features derived from videos. We train our models on data that is two orders-of-magnitude bigger than datasets used in prior work. We perform a thorough exploration of model architectures for combining visual and text features. Our experiments on two corpora (YouCookII and 20bn-something-something-v2) show that the best performing architecture consists of middle fusion of visual and text features, yielding over 25% relative improvement in perplexity. We report analysis that provides insights into why our multimodal language model improves upon a standard RNN language model.