 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Language Generation: Formulation, Methods, and Evaluation
Paper and Code
Jul 31, 2020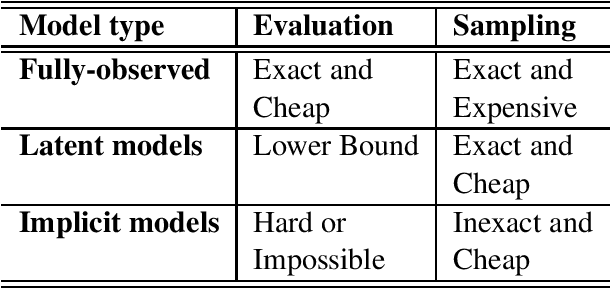

Recent advances in neural network-based generative modeling have reignited the hopes in having computer systems capable of seamlessly conversing with humans and able to understand natural language. Neural architectures have been employed to generate text excerpts to various degrees of success, in a multitude of contexts and tasks that fulfil various user needs. Notably, high capacity deep learning models trained on large scale datasets demonstrate unparalleled abilities to learn patterns in the data even in the lack of explicit supervision signals, opening up a plethora of new possibilities regarding producing realistic and coherent texts. While the field of natural language generation is evolving rapidly, there are still many open challenges to address. In this survey we formally define and categorize the problem of natural language generation. We review particular application tasks that are instantiations of these general formulations, in which generating natural language is of practical importance. Next we include a comprehensive outline of methods and neural architectures employed for generating diverse texts. Nevertheless, there is no standard way to assess the quality of text produced by these generative models, which constitutes a serious bottleneck towards the progress of the field. To this end, we also review current approaches to evaluating natural language generation systems. We hope this survey will provide an informative overview of formulations, methods, and assessments of neural natural language generation.