 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Data-Dependent Transform for Learned Image Compression
Paper and Code
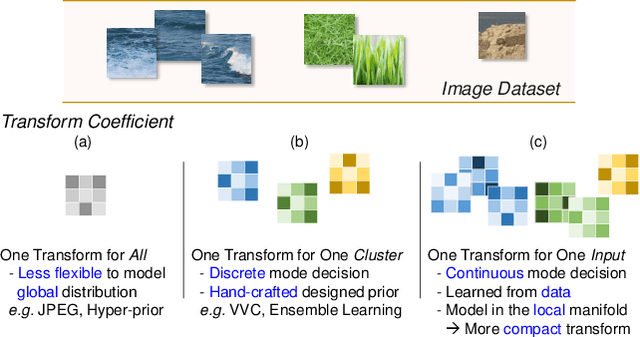
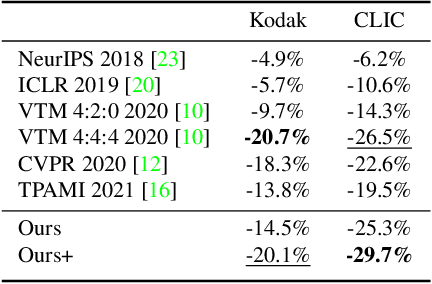
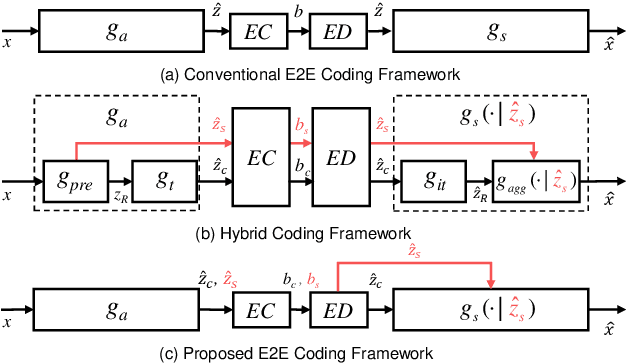
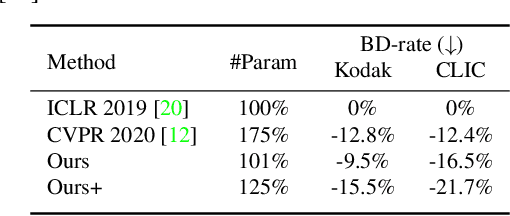
Learned image compression has achieved great success due to its excellent modeling capacity, but seldom further considers the Rate-Distortion Optimization (RDO) of each input image. To explore this potential in the learned codec, we make the first attempt to build a neural data-dependent transform and introduce a continuous online mode decision mechanism to jointly optimize the coding efficiency for each individual image. Specifically, apart from the image content stream, we employ an additional model stream to generate the transform parameters at the decoder side. The presence of a model stream enables our model to learn more abstract neural-syntax, which helps cluster the latent representations of images more compactly. Beyond the transform stage, we also adopt neural-syntax based post-processing for the scenarios that require higher quality reconstructions regardless of extra decoding overhead. Moreover, the involvement of the model stream further makes it possible to optimize both the representation and the decoder in an online way, i.e. RDO at the testing time. It is equivalent to a continuous online mode decision, like coding modes in the traditional codecs, to improve the coding efficiency based on the individual input image. The experimental results show the effectiveness of the proposed neural-syntax design and the continuous online mode decision mechanism, demonstrating the superiority of our method in coding efficiency compared to the latest conventional standard Versatile Video Coding (VVC) and other state-of-the-art learning-based methods.