 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Combinatorial Clustered Bandits for Recommendation Systems
Paper and Code
Oct 18, 2024
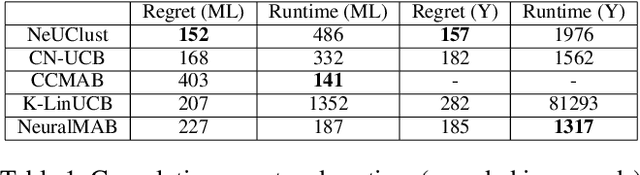
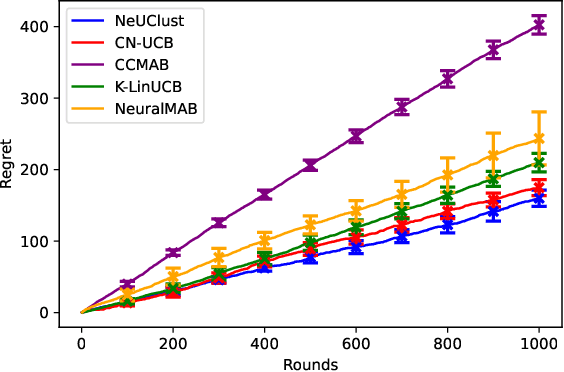

We consider the contextual combinatorial bandit setting where in each round, the learning agent, e.g., a recommender system, selects a subset of "arms," e.g., products, and observes rewards for both the individual base arms, which are a function of known features (called "context"), and the super arm (the subset of arms), which is a function of the base arm rewards. The agent's goal is to simultaneously learn the unknown reward functions and choose the highest-reward arms. For example, the "reward" may represent a user's probability of clicking on one of the recommended products. Conventional bandit models, however, employ restrictive reward function models in order to obtain performance guarantees. We make use of deep neural networks to estimate and learn the unknown reward functions and propose Neural UCB Clustering (NeUClust), which adopts a clustering approach to select the super arm in every round by exploiting underlying structure in the context space. Unlike prior neural bandit works, NeUClust uses a neural network to estimate the super arm reward and select the super arm, thus eliminating the need for a known optimization oracle. We non-trivially extend prior neural combinatorial bandit works to prove that NeUClust achieves $\widetilde{O}\left(\widetilde{d}\sqrt{T}\right)$ regret, where $\widetilde{d}$ is the effective dimension of a neural tangent kernel matrix, $T$ the number of rounds. Experiments on real world recommendation datasets show that NeUClust achieves better regret and reward than other contextual combinatorial and neural bandit algorithms.