 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Architecture Search without Training
Paper and Code
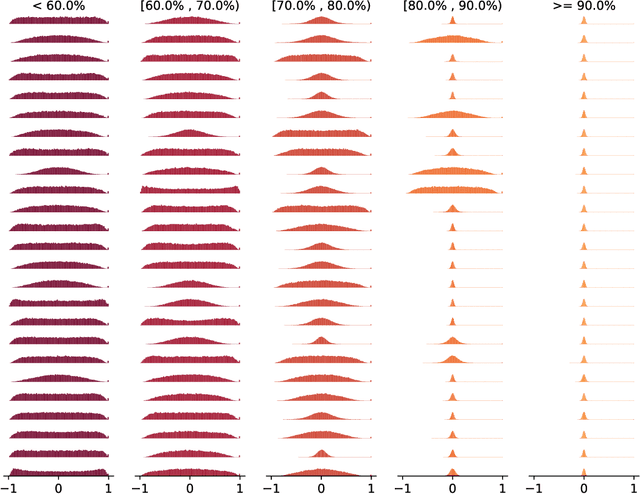
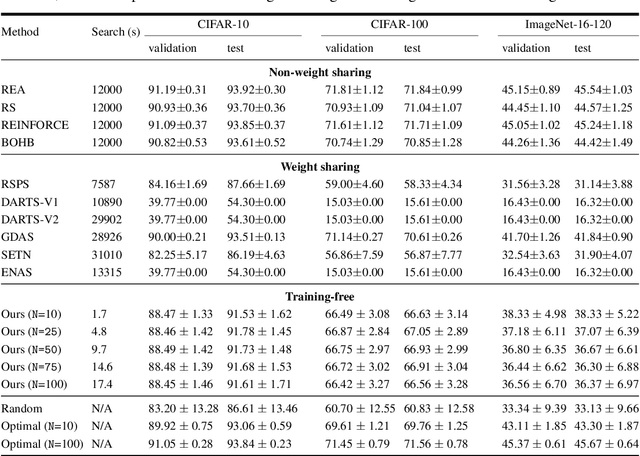

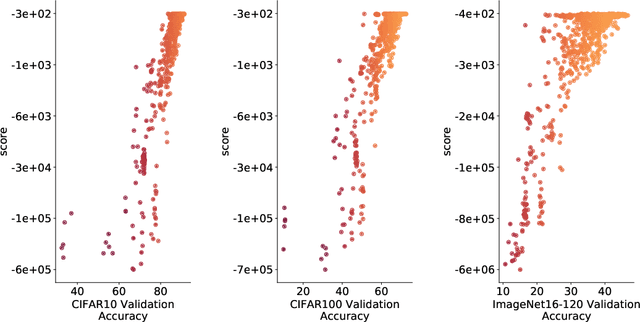
The time and effort involved in hand-designing deep neural networks is immense. This has prompted the development of Neural Architecture Search (NAS) techniques to automate this design. However, NAS algorithms tend to be extremely slow and expensive; they need to train vast numbers of candidate networks to inform the search process. This could be remedied if we could infer a network's trained accuracy from its initial state. In this work, we examine how the linear maps induced by data points correlate for untrained network architectures in the NAS-Bench-201 search space, and motivate how this can be used to give a measure of modelling flexibility which is highly indicative of a network's trained performance. We incorporate this measure into a simple algorithm that allows us to search for powerful networks without any training in a matter of seconds on a single GPU. Code to reproduce our experiments is available at https://github.com/BayesWatch/nas-without-training.