 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeΩ-Net : Fully Automatic, Multi-View Cardiac MR Detection, Orientation, and Segmentation with Deep Neural Networks
Paper and Code
Mar 20, 2018
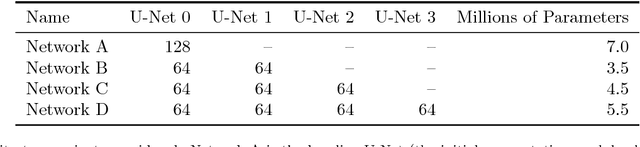

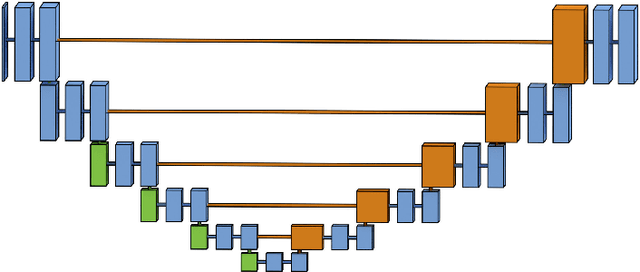
Pixelwise segmentation of the left ventricular (LV) myocardium and the four cardiac chambers in 2-D steady state free precession (SSFP) cine sequences is an essential preprocessing step for a wide range of analyses. Variability in contrast, appearance, orientation, and placement of the heart between patients, clinical views, scanners, and protocols makes fully automatic semantic segmentation a notoriously difficult problem. Here, we present ${\Omega}$-Net (Omega-Net): a novel convolutional neural network (CNN) architecture for simultaneous localization, transformation into a canonical orientation, and semantic segmentation. First, an initial segmentation is performed on the input image, second, the features learned during this initial segmentation are used to predict the parameters needed to transform the input image into a canonical orientation, and third, a final segmentation is performed on the transformed image. In this work, ${\Omega}$-Nets of varying depths were trained to detect five foreground classes in any of three clinical views (short axis, SA, four-chamber, 4C, two-chamber, 2C), without prior knowledge of the view being segmented. The architecture was trained on a cohort of patients with hypertrophic cardiomyopathy and healthy control subjects. Network performance as measured by weighted foreground intersection-over-union (IoU) was substantially improved in the best-performing ${\Omega}$- Net compared with U-Net segmentation without localization or orientation. In addition, {\Omega}-Net was retrained from scratch on the 2017 MICCAI ACDC dataset, and achieves state-of-the-art results on the LV and RV bloodpools, and performed slightly worse in segmentation of the LV myocardium. We conclude this architecture represents a substantive advancement over prior approaches, with implications for biomedical image segmentation more generally.