 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEO-BENCH: Evaluating Robustness of Large Language Models with Neologisms
Paper and Code
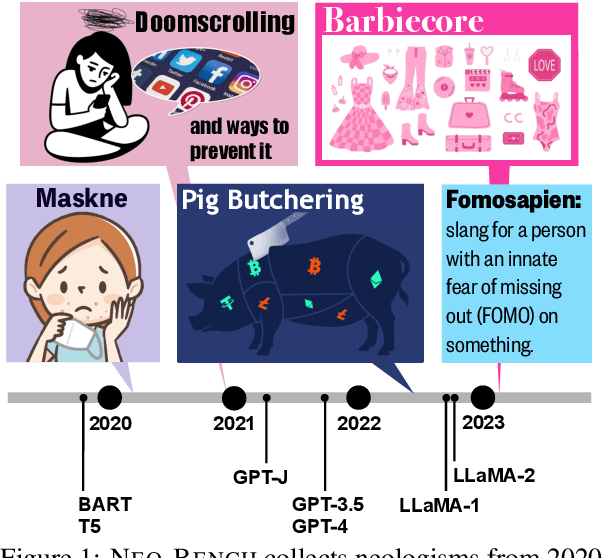



The performance of Large Language Models (LLMs) degrades from the temporal drift between data used for model training and newer text seen during inference. One understudied avenue of language change causing data drift is the emergence of neologisms -- new word forms -- over time. We create a diverse resource of recent English neologisms by using several popular collection methods. We analyze temporal drift using neologisms by comparing sentences containing new words with near-identical sentences that replace neologisms with existing substitute words. Model performance is nearly halved in machine translation when a single neologism is introduced in a sentence. Motivated by these results, we construct a benchmark to evaluate LLMs' ability to generalize to neologisms with various natural language understanding tasks and model perplexity. Models with later knowledge cutoff dates yield lower perplexities and perform better in downstream tasks. LLMs are also affected differently based on the linguistic origins of words, indicating that neologisms are complex for static LLMs to address. We will release our benchmark and code for reproducing our experiments.