 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighborhood-based Pooling for Population-level Label Distribution Learning
Paper and Code
Mar 16, 2020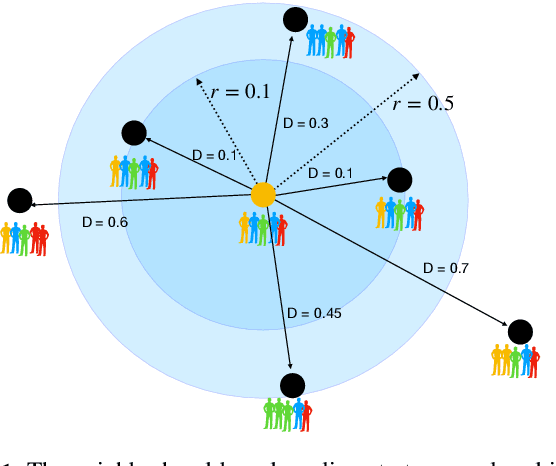
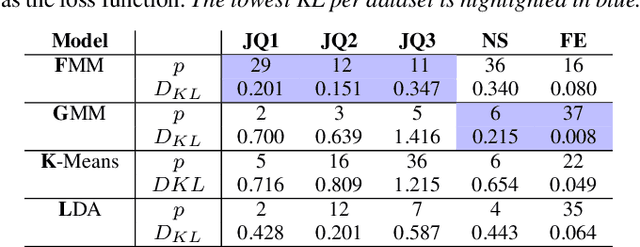
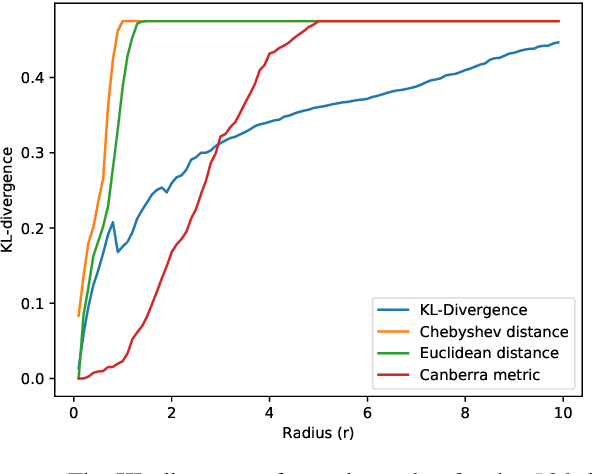
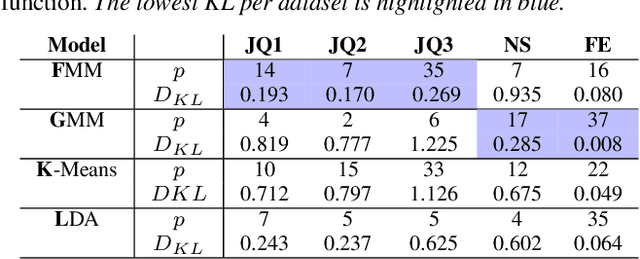
Supervised machine learning often requires human-annotated data. While annotator disagreement is typically interpreted as evidence of noise, population-level label distribution learning (PLDL) treats the collection of annotations for each data item as a sample of the opinions of a population of human annotators, among whom disagreement may be proper and expected, even with no noise present. From this perspective, a typical training set may contain a large number of very small-sized samples, one for each data item, none of which, by itself, is large enough to be considered representative of the underlying population's beliefs about that item. We propose an algorithmic framework and new statistical tests for PLDL that account for sampling size. We apply them to previously proposed methods for sharing labels across similar data items. We also propose new approaches for label sharing, which we call neighborhood-based pooling.