 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegative Samples are at Large: Leveraging Hard-distance Elastic Loss for Re-identification
Paper and Code
Jul 20, 2022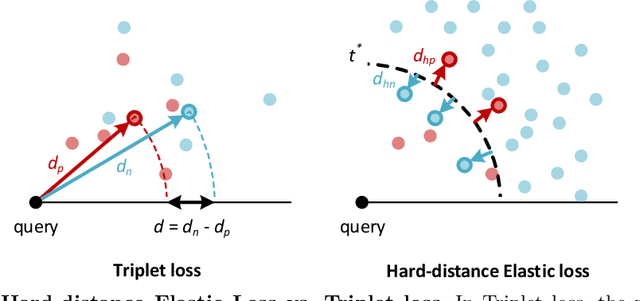
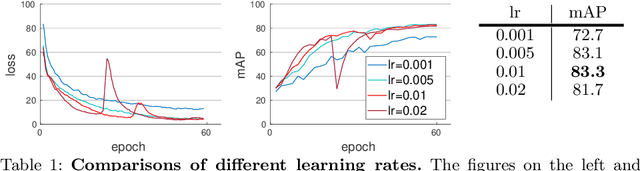
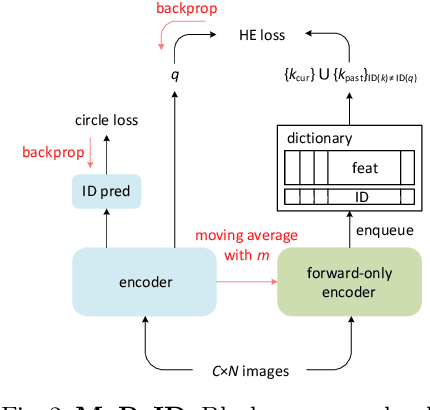
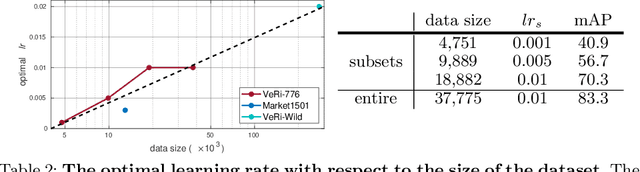
We present a Momentum Re-identification (MoReID) framework that can leverage a very large number of negative samples in training for general re-identification task. The design of this framework is inspired by Momentum Contrast (MoCo), which uses a dictionary to store current and past batches to build a large set of encoded samples. As we find it less effective to use past positive samples which may be highly inconsistent to the encoded feature property formed with the current positive samples, MoReID is designed to use only a large number of negative samples stored in the dictionary. However, if we train the model using the widely used Triplet loss that uses only one sample to represent a set of positive/negative samples, it is hard to effectively leverage the enlarged set of negative samples acquired by the MoReID framework. To maximize the advantage of using the scaled-up negative sample set, we newly introduce Hard-distance Elastic loss (HE loss), which is capable of using more than one hard sample to represent a large number of samples. Our experiments demonstrate that a large number of negative samples provided by MoReID framework can be utilized at full capacity only with the HE loss, achieving the state-of-the-art accuracy on three re-ID benchmarks, VeRi-776, Market-1501, and VeRi-Wild.