 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly Minimax Optimal Reinforcement Learning with Linear Function Approximation
Paper and Code
Jun 23, 2022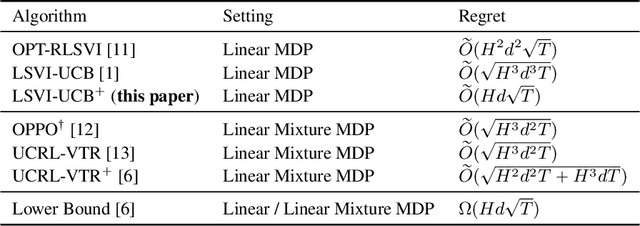
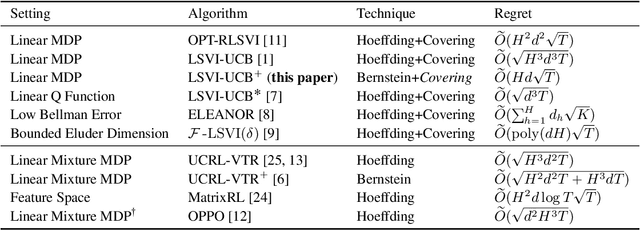
We study reinforcement learning with linear function approximation where the transition probability and reward functions are linear with respect to a feature mapping $\boldsymbol{\phi}(s,a)$. Specifically, we consider the episodic inhomogeneous linear Markov Decision Process (MDP), and propose a novel computation-efficient algorithm, LSVI-UCB$^+$, which achieves an $\widetilde{O}(Hd\sqrt{T})$ regret bound where $H$ is the episode length, $d$ is the feature dimension, and $T$ is the number of steps. LSVI-UCB$^+$ builds on weighted ridge regression and upper confidence value iteration with a Bernstein-type exploration bonus. Our statistical results are obtained with novel analytical tools, including a new Bernstein self-normalized bound with conservatism on elliptical potentials, and refined analysis of the correction term. To the best of our knowledge, this is the first minimax optimal algorithm for linear MDPs up to logarithmic factors, which closes the $\sqrt{Hd}$ gap between the best known upper bound of $\widetilde{O}(\sqrt{H^3d^3T})$ in \cite{jin2020provably} and lower bound of $\Omega(Hd\sqrt{T})$ for linear MDPs.