 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearest Neighbour Based Estimates of Gradients: Sharp Nonasymptotic Bounds and Applications
Paper and Code

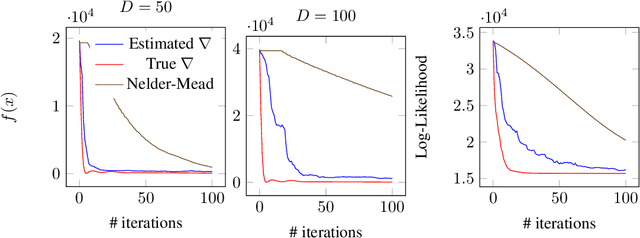
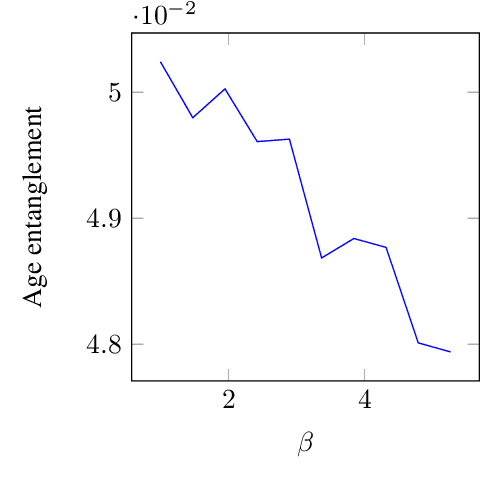
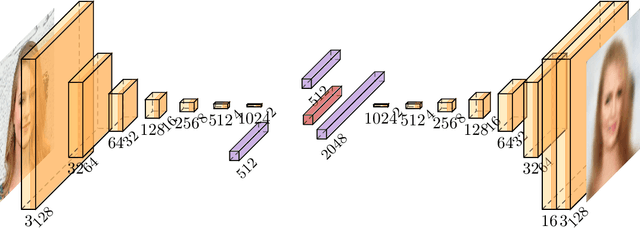
Motivated by a wide variety of applications, ranging from stochastic optimization to dimension reduction through variable selection, the problem of estimating gradients accurately is of crucial importance in statistics and learning theory. We consider here the classic regression setup, where a real valued square integrable r.v. $Y$ is to be predicted upon observing a (possibly high dimensional) random vector $X$ by means of a predictive function $f(X)$ as accurately as possible in the mean-squared sense and study a nearest-neighbour-based pointwise estimate of the gradient of the optimal predictive function, the regression function $m(x)=\mathbb{E}[Y\mid X=x]$. Under classic smoothness conditions combined with the assumption that the tails of $Y-m(X)$ are sub-Gaussian, we prove nonasymptotic bounds improving upon those obtained for alternative estimation methods. Beyond the novel theoretical results established, several illustrative numerical experiments have been carried out. The latter provide strong empirical evidence that the estimation method proposed works very well for various statistical problems involving gradient estimation, namely dimensionality reduction, stochastic gradient descent optimization and quantifying disentanglement.