 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear Optimal Stratified Sampling
Paper and Code
Jul 26, 2019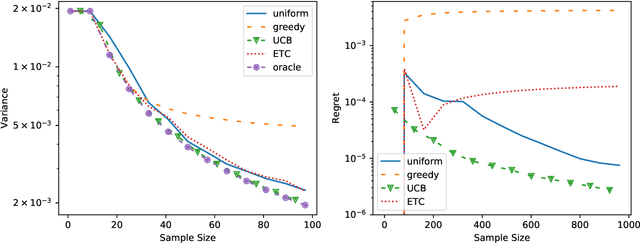

The performance of a machine learning system is usually evaluated by using i.i.d.\ observations with true labels. However, acquiring ground truth labels is expensive, while obtaining unlabeled samples may be cheaper. Stratified sampling can be beneficial in such settings and can reduce the number of true labels required without compromising the evaluation accuracy. Stratified sampling exploits statistical properties (e.g., variance) across strata of the unlabeled population, though usually under the unrealistic assumption that these properties are known. We propose two new algorithms that simultaneously estimate these properties and optimize the evaluation accuracy. We construct a lower bound to show the proposed algorithms (to log-factors) are rate optimal. Experiments on synthetic and real data show the reduction in label complexity that is enabled by our algorithms.