 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Sample Complexity Bounds for Constrained MDPs
Paper and Code
Jun 13, 2022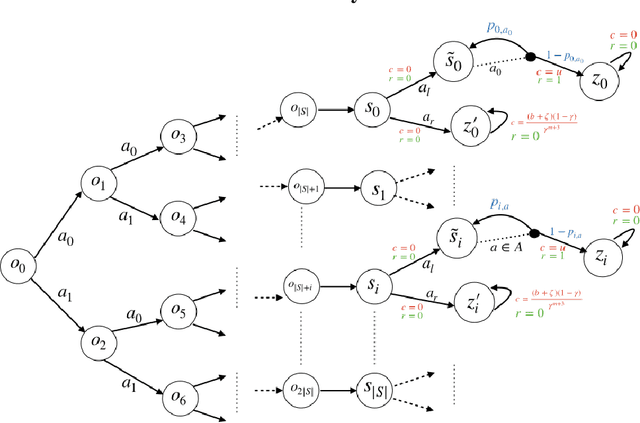

In contrast to the advances in characterizing the sample complexity for solving Markov decision processes (MDPs), the optimal statistical complexity for solving constrained MDPs (CMDPs) remains unknown. We resolve this question by providing minimax upper and lower bounds on the sample complexity for learning near-optimal policies in a discounted CMDP with access to a generative model (simulator). In particular, we design a model-based algorithm that addresses two settings: (i) relaxed feasibility, where small constraint violations are allowed, and (ii) strict feasibility, where the output policy is required to satisfy the constraint. For (i), we prove that our algorithm returns an $\epsilon$-optimal policy with probability $1 - \delta$, by making $\tilde{O}\left(\frac{S A \log(1/\delta)}{(1 - \gamma)^3 \epsilon^2}\right)$ queries to the generative model, thus matching the sample-complexity for unconstrained MDPs. For (ii), we show that the algorithm's sample complexity is upper-bounded by $\tilde{O} \left(\frac{S A \, \log(1/\delta)}{(1 - \gamma)^5 \, \epsilon^2 \zeta^2} \right)$ where $\zeta$ is the problem-dependent Slater constant that characterizes the size of the feasible region. Finally, we prove a matching lower-bound for the strict feasibility setting, thus obtaining the first near minimax optimal bounds for discounted CMDPs. Our results show that learning CMDPs is as easy as MDPs when small constraint violations are allowed, but inherently more difficult when we demand zero constraint violation.