 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear Neighbor: Who is the Fairest of Them All?
Paper and Code
Jun 06, 2019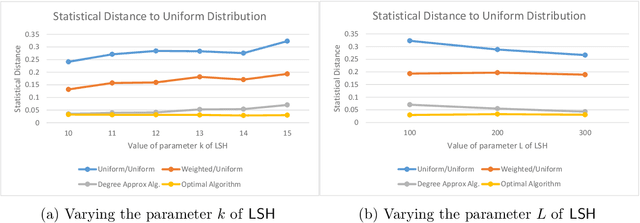
$\newcommand{\ball}{\mathbb{B}}\newcommand{\dsQ}{{\mathcal{Q}}}\newcommand{\dsS}{{\mathcal{S}}}$In this work we study a fair variant of the near neighbor problem. Namely, given a set of $n$ points $P$ and a parameter $r$, the goal is to preprocess the points, such that given a query point $q$, any point in the $r$-neighborhood of the query, i.e., $\ball(q,r)$, have the same probability of being reported as the near neighbor. We show that LSH based algorithms can be made fair, without a significant loss in efficiency. Specifically, we show an algorithm that reports a point in the $r$-neighborhood of a query $q$ with almost uniform probability. The query time is proportional to $O\bigl( \mathrm{dns}(q.r) \dsQ(n,c) \bigr)$, and its space is $O(\dsS(n,c))$, where $\dsQ(n,c)$ and $\dsS(n,c)$ are the query time and space of an LSH algorithm for $c$-approximate near neighbor, and $\mathrm{dns}(q,r)$ is a function of the local density around $q$. Our approach works more generally for sampling uniformly from a sub-collection of sets of a given collection and can be used in a few other applications. Finally, we run experiments to show performance of our approach on real data.