 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating to the Best Policy in Markov Decision Processes
Paper and Code
Jun 05, 2021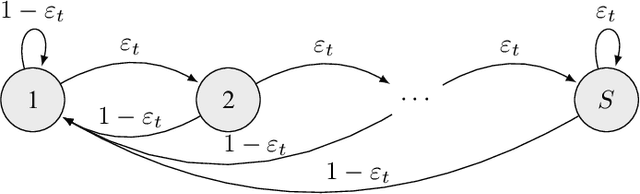

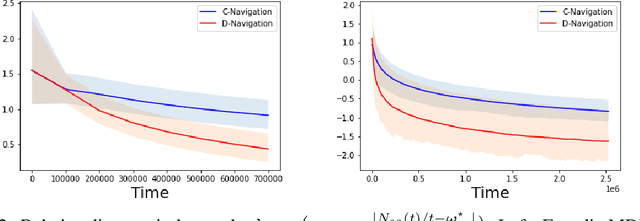
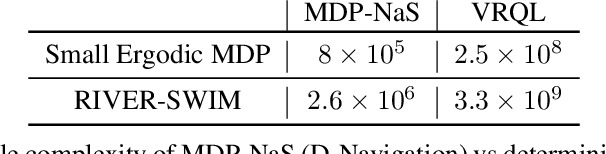
We investigate the classical active pure exploration problem in Markov Decision Processes, where the agent sequentially selects actions and, from the resulting system trajectory, aims at identifying the best policy as fast as possible. We propose an information-theoretic lower bound on the average number of steps required before a correct answer can be given with probability at least $1-\delta$. This lower bound involves a non-convex optimization problem, for which we propose a convex relaxation. We further provide an algorithm whose sample complexity matches the relaxed lower bound up to a factor $2$. This algorithm addresses general communicating MDPs; we propose a variant with reduced exploration rate (and hence faster convergence) under an additional ergodicity assumption. This work extends previous results relative to the \emph{generative setting}~\cite{marjani2020adaptive}, where the agent could at each step observe the random outcome of any (state, action) pair. In contrast, we show here how to deal with the \emph{navigation constraints}. Our analysis relies on an ergodic theorem for non-homogeneous Markov chains which we consider of wide interest in the analysis of Markov Decision Processes.