 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Shadows: Unveiling Effective Disturbances for Modern AI Content Detectors
Paper and Code
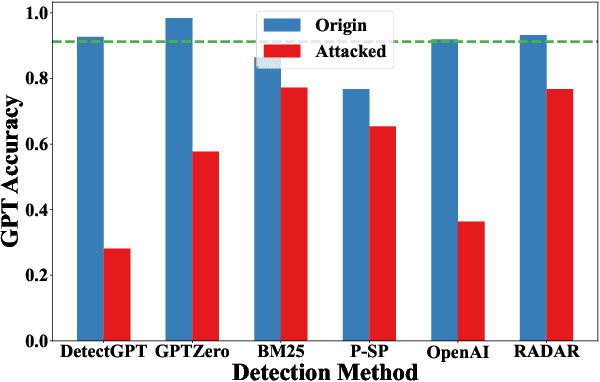



With the launch of ChatGPT, large language models (LLMs) have attracted global attention. In the realm of article writing, LLMs have witnessed extensive utilization, giving rise to concerns related to intellectual property protection, personal privacy, and academic integrity. In response, AI-text detection has emerged to distinguish between human and machine-generated content. However, recent research indicates that these detection systems often lack robustness and struggle to effectively differentiate perturbed texts. Currently, there is a lack of systematic evaluations regarding detection performance in real-world applications, and a comprehensive examination of perturbation techniques and detector robustness is also absent. To bridge this gap, our work simulates real-world scenarios in both informal and professional writing, exploring the out-of-the-box performance of current detectors. Additionally, we have constructed 12 black-box text perturbation methods to assess the robustness of current detection models across various perturbation granularities. Furthermore, through adversarial learning experiments, we investigate the impact of perturbation data augmentation on the robustness of AI-text detectors. We have released our code and data at https://github.com/zhouying20/ai-text-detector-evaluation.