Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Gradient Deep Q-learning
Paper and Code
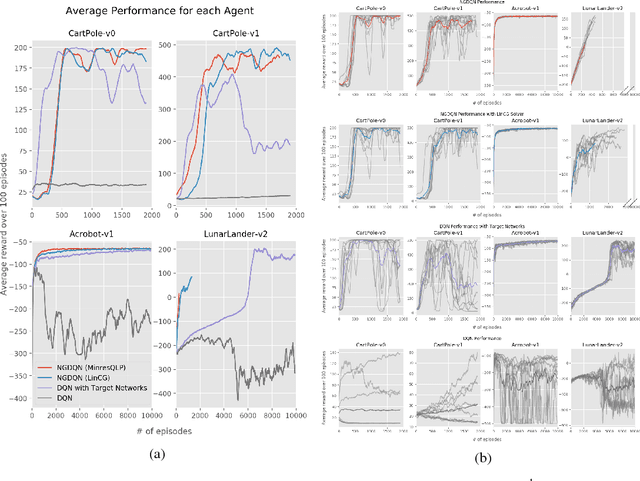



This paper presents findings for training a Q-learning reinforcement learning agent using natural gradient techniques. We compare the original deep Q-network (DQN) algorithm to its natural gradient counterpart (NGDQN), measuring NGDQN and DQN performance on classic controls environments without target networks. We find that NGDQN performs favorably relative to DQN, converging to significantly better policies faster and more frequently. These results indicate that natural gradient could be used for value function optimization in reinforcement learning to accelerate and stabilize training.
View paper on