Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatcat: Weakly Supervised Text Classification with Naturally Annotated Datasets
Paper and Code
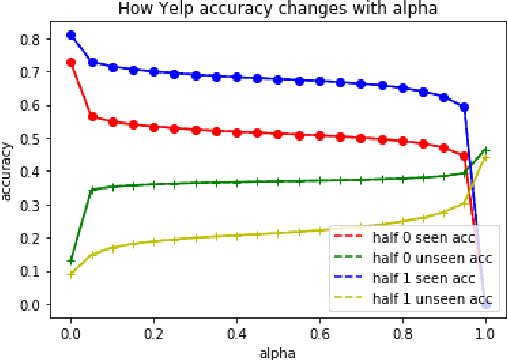
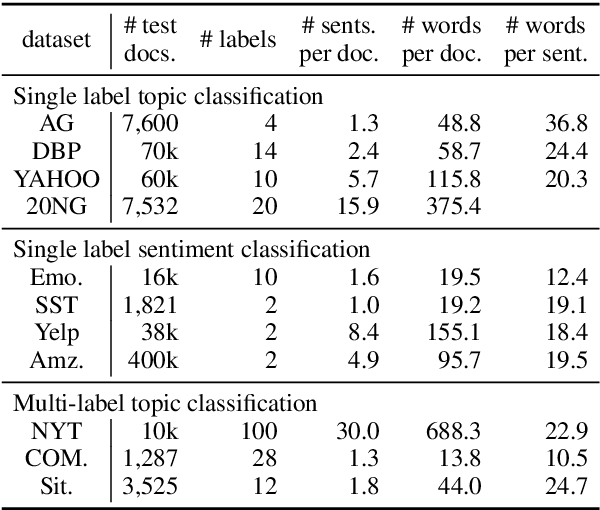
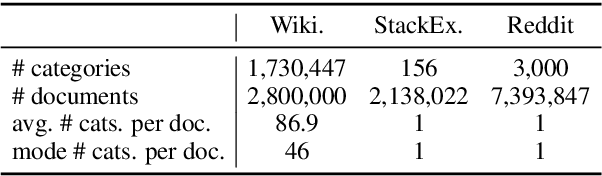
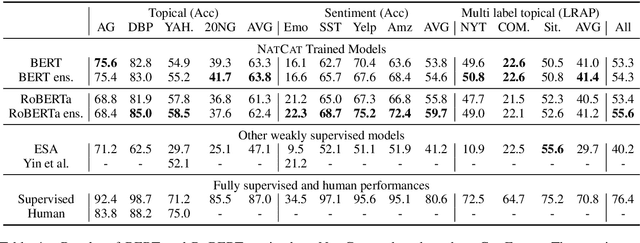
We seek to improve text classification by leveraging naturally annotated data. In particular, we construct a general purpose text categorization dataset (NatCat) from three online resources: Wikipedia, Reddit, and Stack Exchange. These datasets consist of document-category pairs derived from manual curation that occurs naturally by their communities. We build general purpose text classifiers by training on NatCat and evaluate them on a suite of 11 text classification tasks (CatEval). We benchmark different modeling choices and dataset combinations, and show how each task benefits from different NatCat training resources.
View paper on