 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNamed entity recognition in chemical patents using ensemble of contextual language models
Paper and Code

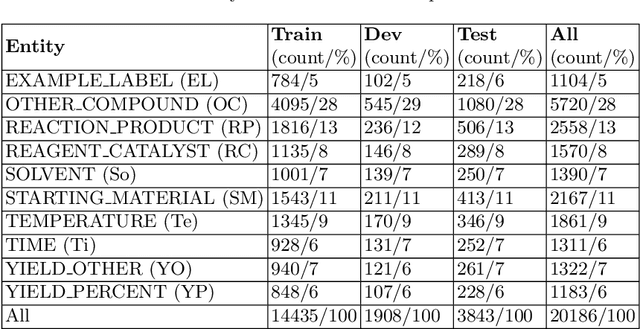

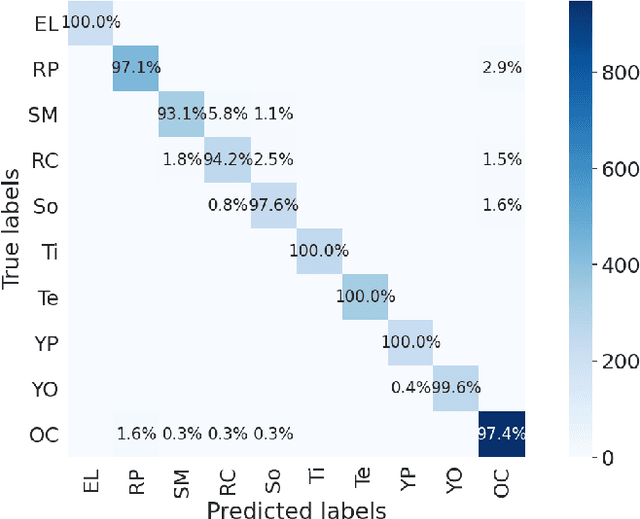
Chemical patent documents describe a broad range of applications holding key information, such as chemical compounds, reactions, and specific properties. However, the key information should be enabled to be utilized in downstream tasks. Text mining provides means to extract relevant information from chemical patents through information extraction techniques. As part of the Information Extraction task of the Cheminformatics Elseiver Melbourne University challenge, in this work we study the effectiveness of contextualized language models to extract reaction information in chemical patents. We compare transformer architectures trained on a generic corpus with models specialised in chemistry patents, and propose a new model based on the combination of existing architectures. Our best model, based on the ensemble approach, achieves an exact F1-score of 92.30% and a relaxed F1 -score of 96.24%. We show that the ensemble of contextualized language models provides an effective method to extract information from chemical patents. As a next step, we will investigate the effect of transformer language models pre-trained in chemical patents.